
Elevate modern apps with TiDB.
Authors: Chunhui Liu and Chao Hong (Database Administrators at Shopee)
Shopee is the leading e-commerce platform in Southeast Asia and Taiwan. It is a platform tailored for the region, providing customers with an easy, secure and fast online shopping experience through strong payment and logistical support.
Shopee aims to continually enhance its platform and become the region’s e-commerce destination of choice. Shopee has a wide selection of product categories ranging from consumer electronics to home & living, health & beauty, baby & toys, fashion and fitness equipment.
Shopee, a Sea company, was first launched in Singapore in 2015, and has since expanded its reach to Malaysia, Thailand, Taiwan, Indonesia, Vietnam and the Philippines. Sea is a leader in digital entertainment, e-commerce and digital financial services across Greater Southeast Asia. Sea’s mission is to better the lives of consumers and small businesses with technology, and is listed on the NYSE under the symbol SE.

As our business boomed, our team faced severe challenges in scaling our backend system to meet the demand. Fortunately, we found TiDB, a MySQL-compatible NewSQL hybrid transactional and analytical processing (HTAP) database, built and supported by PingCAP and its open-source community. Now we can provide better service and experience for our users without worrying about our database capacity.
Currently, we have deployed two TiDB clusters totaling 60 nodes in our risk control and audit log systems. In this post, we will elaborate on why we chose TiDB, how we are using it, and our future plan for TiDB inside our infrastructure.
TiDB in a nutshell is a platform comprised of multiple components that when used together becomes a NewSQL database that has HTAP capabilities.

Inside the TiDB platform, the main components are as follows:
Beyond these main components, TiDB also has an ecosystem of tools, such as Ansible scripts for quick deployment, Syncer and DM for seamless migration from MySQL, and TiDB Binlog, which is used to collect the logical changes made to a TiDB cluster and provide incremental backup and replication to the downstream (TiDB, Kafka or MySQL).
Our risk control system detects abnormal behaviors and fraudulent transactions from our internal logs of orders and user behaviors. This log was stored in MySQL and sharded into 100 tables based on USER_ID.
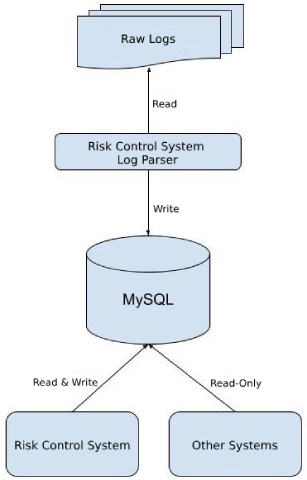
This approach began to show its limitations as the major shopping season approached. During one major 2018 promotion event, the number of orders exceeded 11 million, 4.5 times larger than the previous year. On December 12, 2018, another major online shopping day known as “Double 12”, the number of orders reached an all-time high in Shopee history — 12 million.
Although we enabled InnoDB Transparent Page Compression to compress the data size by half and increased the MySQL server storage space from 2.5TB to 6TB as a temporary fix, we knew we needed a horizontally scalable database solution for the long term.
Before choosing TiDB, we carefully researched and compared the pros and cons of MySQL sharding solution with the TiDB platform. Here was what our comparison found.
To continue with our current sharding solution, we would need to re-shard the data in the existing 100 tables to 1,000 or perhaps 10,000 tables and then distribute these shards among different MySQL instances.
Advantage:
Disadvantages:
Advantages:
Disadvantage:
After a thorough evaluation, we decided to be an early adopter of TiDB, given all its attractive advantages, and TiDB turned out to be a perfect match for our services. Here is how we migrated the traffic and how we are currently using TiDB in our system.
Our traffic migration process from MySQL to TiDB is as follows:

During the traffic migration process, we benefited a great deal from the doublewrite approach:
rc_sg, rc_my, rc_ph, …, rc_tw) according to user regions. This way, we could customize a specific data structure for each region.Initially, we migrated 4TB of data from MySQL to a TiDB cluster that consisted of 14 nodes, comprising of 3 PD nodes, 3 TiDB nodes and 8 TiKV nodes.
TiKV nodes
PD nodes and TiDB nodes
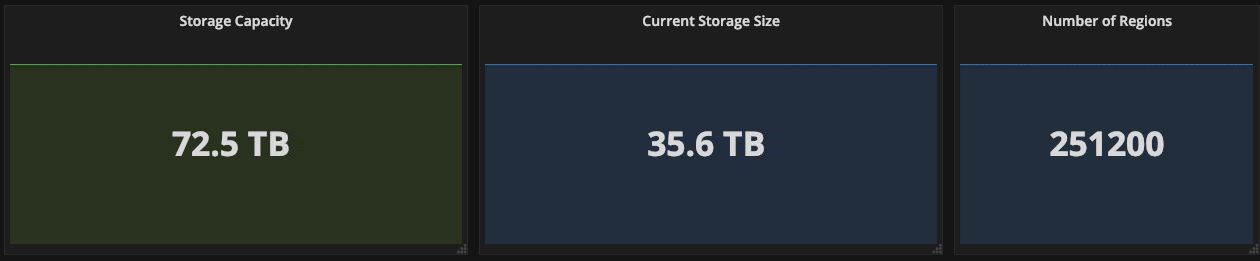
So far, our system has been running smoothly with the data volume growing to 35TB at the time of this writing (See Figure 5). After scaling our capacity twice, there are now 42 nodes in the cluster.

Generally, the total value of QPS (queries per second) (for both Error and OK queries) of TiDB for risk control logs is less than 20,000. But during the December 12 shopping holiday the QPS jumped to more than 100,000.
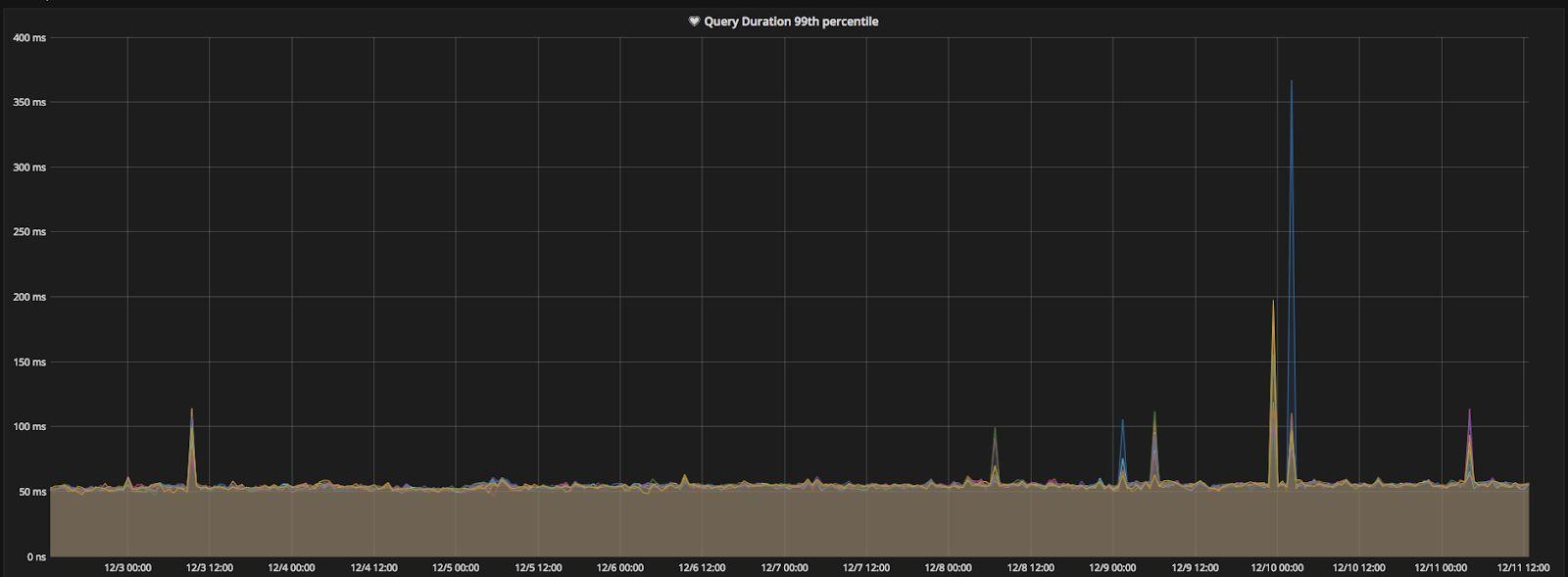
Although the data size has grown eightfold over the past 6 months, the whole cluster still maintains a stable query response time. Generally, the 99th percentile response time was less than 60ms (See Figure 7), which is very good for a risk control system mainly processing complex SQL queries.
While we have been happy with our experience with TiDB, the adoption was not without challenges. One issue we have encountered is that after adding new nodes to an existing TiKV cluster to expand our storage capacity, it took a long time to rebalance data — roughly 24 hours to rebalance about 1TB of new data. Thus, to better prepare for this bottleneck, we would usually do this scaling a few days before any of our promotional campaigns when we know traffic will spike, and closely monitor the progress of data rebalancing. We also recommend setting the scheduling related parameters in PD to a larger value.
Another issue is that TiDB’s MySQL compatibility is not fully complete; for example, TiDB does not currently support the SHOW CREATE USER syntax, which is related to MySQL user privilege. Instead, we have to read the system table (mysql.user) to check the basic information of a database account. The good thing is the PingCAP team is very transparent about MySQL features that are currently not supported in TiDB, and is responsive to our requests — a pull request is already filed for this particular issue.
With one year’s worth of TiDB experience under our belt, we feel confident in TiDB’s potential and have plans to expand its usage inside Shopee’s infrastructure in the following ways.
Currently, our TiDB clusters serve large amounts of non-transactional data. We plan to evaluate the migration of some transactional data from MySQL to TiDB.
We plan to use TiDB as part of our MySQL replication scheme, where TiDB will serve as the MySQL secondary and data in MySQL will be replicated to TiDB in real time.
This secondary-like TiDB cluster will then support analytical queries for our business intelligence system, drawing insights from our data. Since these queries are read-only and often require a full table scan or index scan, TiDB is much better suited to process these queries than MySQL. We also plan to use TiSpark to read data from TiKV directly if faster analytical query performance is needed.
Currently, we are running TiDB clusters on bare metal. It takes our DBAs substantial amount of time to maintain the hardware, network, and OS of our servers. In the future, we intend to run TiDB on our container platform and build up a toolset to achieve self-service resource application and configuration management. Then our staff will be freed from the daily grinds of operation and maintenance.
We would like to thank every PingCAP member who has helped us during the past year. They have been quick to respond, attentive in following up our project, and provided helpful advice along the way. We have also relied on the TiDB documentation, which is informative and clearly-structured.

Elevate modern apps with TiDB.