

Managing large-scale data efficiently is a critical challenge for modern databases, especially when dealing with time-sensitive data that can quickly become outdated. Starting from TiDB 6.5 and becoming generally available in TiDB 7.0, TTL (Time To Live) automates the deletion of expired data, offering a powerful, customizable solution for maintaining data freshness while minimizing operational overhead.
By allowing users to configure expiration rules and run periodic deletion jobs, TiDB TTL not only simplifies compliance with data retention policies but also optimizes storage usage and enhances system performance. By configuring TTL attributes on a table, TiDB periodically checks for expired records and removes them without manual intervention. For example:
CREATE TABLE t (
id INT UNSIGNED PRIMARY KEY,
created_at DATETIME
)
TTL = created_at + INTERVAL 10 HOUR
TTL_JOB_INTERVAL = '1h';This configuration ensures that records are deleted every hour when created_at + INTERVAL 10 HOUR is less than the current time, helping to maintain data freshness and optimize storage usage.
In this blog, we’ll explore the journey behind the design and implementation of TiDB’s TTL capability. We’ll dive into:
- How to configure TTL-related system variables for better performance and reduced impact on online workloads.
- The thought process and trade-offs behind implementing TTL functionality in a distributed SQL database.
- Key technical insights to help users fully leverage the capabilities of TTL for managing expired data efficiently.
Designing TiDB TTL: Evaluating Methods and Trade-offs
When implementing the TTL feature in TiDB, the team evaluated different methods for automatically cleaning up expired data. Here’s a breakdown of the two main approaches considered, and why TiDB ultimately chose the periodic SQL-based deletion method.
Option 1: Using RocksDB Compaction Filter
This method deletes expired data during LSM Tree compaction. TiKV’s RawKV TTL already uses this functionality. However, applying this approach to TiDB presented several challenges:
- Data Format Changes: Each key-value pair would need an expiration time, requiring extensive read/write operations during schema updates (DDL).
- Consistency Issues: Keeping table data and indexes consistent is complex in a distributed system, especially when indexes and data might reside on different TiKV nodes.
- Conflicts with Transactions: TiDB’s transaction model (MVCC) and locking mechanisms would be hard to maintain. For instance:
- Removing newer versions could inadvertently expose older, outdated versions.
- Prematurely deleting locked data, causing errors.
While it’s possible to mitigate some of these issues (e.g., delaying deletion or filtering expired data during reads), this approach introduces too many risks and would require invasive changes to TiDB’s architecture.
Verdict: This method contains high complexity, risk of breaking correctness, and significant impact on other features.
Option 2: Periodic Deletion with SQL Statements
This approach uses SQL queries to periodically identify and delete expired data. While simpler and safer, it also comes with its own trade-offs:
- Advantages:
- Preserves Correctness: SQL-based deletion ensures table data and indexes remain consistent, aligning naturally with TiDB’s transaction model.
- Isolated Design: This method is less invasive, keeping TTL functionality separate from other features.
- Challenges:
- Resource Usage: Full table scans are required if no indexes are present, which can be resource-intensive.
- Indexing Limitations: Adding indexes on time-based columns (e.g.,
created_at) is generally discouraged in distributed databases, as it can create write hotspots and degrade performance.
Despite these challenges, TiDB focused on optimizing for scenarios without indexes, using full table scans for simplicity and compatibility.
Verdict: This method balances correctness, simplicity, and compatibility with TiDB’s architecture.
Why TiDB Chose Periodic Deletion
The periodic SQL-based deletion approach offered the best trade-off between feasibility, correctness, and minimal disruption to existing features. It avoids the complexity of deeply modifying TiDB’s architecture while ensuring reliable cleanup of expired data. Though resource-intensive in some scenarios, the design prioritizes safety and maintainability, making it the ideal solution for TiDB’s TTL feature.
How TiDB TTL Works
TiDB’s TTL feature automates the deletion of expired data by periodically triggering cleanup jobs and executing them efficiently. This functionality involves two key processes: scheduling TTL jobs and running them within defined operational constraints.
Scheduling TiDB TTL Jobs
TTL jobs are triggered at regular intervals, which can be configured to balance resource consumption and the need for timely cleanup.
- Default Behavior: TTL jobs run every 24 hours for each table.
- Customization: The
TTL_JOB_INTERVALproperty allows adjustments:- Longer intervals reduce resource usage for non-critical cleanup.
- Shorter intervals ensure quicker removal of expired data.
TiDB tracks the status of TTL jobs in the mysql.tidb_ttl_table_status system table, which includes key columns such as:
last_job_start_time: Records the start time of the most recent TTL job.current_job_id: Indicates whether a TTL job is currently running (empty if no job is active).
Cron-Like Triggering:
- Every 10 seconds, TiDB nodes check
mysql.tidb_ttl_table_statusto determine if any tables require a new TTL job.- A new job is triggered if:
- No current TTL job is running (
current_job_idis empty). - The interval since the last job exceeds the configured value (
last_job_start_time + TTL_JOB_INTERVAL < NOW()).
- No current TTL job is running (
- A new job is triggered if:
- Once triggered, the TiDB node updates the
current_*fields in a transaction, ensuring that only one node starts the job and preventing redundant executions.
Understanding the Status Table
TiDB records metadata about TTL jobs in the mysql.tidb_ttl_table_status table. Here’s what some key fields represent:
| Column | Description |
table_id | Unique identifier for the table the TTL job applies to. |
last_job_id | UUID of the last completed TTL job for this table. |
last_job_start_time | Timestamp when the most recent TTL job started. |
last_job_finish_time | Timestamp when the most recent TTL job finished. |
last_job_summary | JSON summary of the results, including rows scanned, successfully deleted, and errors (if any). |
current_job_id | UUID of the currently running TTL job (empty if no job is active). |
current_job_owner_id | Identifier of the TiDB node currently handling this TTL job. |
current_job_owner_addr | Address of the TiDB node managing the current job. |
current_job_start_time | Timestamp when the current TTL job began. |
current_job_state | State of the active TTL job, if any (e.g., running, paused). |
Example Output:
TABLE mysql.tidb_ttl_table_status LIMIT 1\G
*************************** 1. row ***************************
table_id: 85
parent_table_id: 85
table_statistics: NULL
last_job_id: 0b4a6d50-3041-4664-9516-5525ee6d9f90
last_job_start_time: 2023-02-15 20:43:46
last_job_finish_time: 2023-02-15 20:44:46
last_job_ttl_expire: 2023-02-15 19:43:46
last_job_summary: {"total_rows":4369519,"success_rows":4369519,"error_rows":0,"total_scan_task":64,"scheduled_scan_task":64,"finished_scan_task":64}
current_job_id: NULL
current_job_owner_id: NULL
current_job_owner_addr: NULL
current_job_owner_hb_time: NULL
current_job_start_time: NULL
current_job_ttl_expire: NULL
current_job_state: NULL
current_job_status: NULL
current_job_status_update_time: NULLThis table helps coordinate TTL jobs across TiDB nodes and ensures that only one node is managing a given job at a time.
Running TiDB TTL Jobs During Low-Traffic Hours
Database workloads often have off-peak times when system load is lower (e.g., nighttime). To take advantage of this, TiDB lets you define time windows during which these jobs can run.
Time Window Settings:
tidb_ttl_job_schedule_window_start_time: Defines the earliest time TTL jobs can run each day.tidb_ttl_job_schedule_window_end_time: Sets the latest time TTL jobs can run.
By default, TTL jobs run between 00:00 UTC and 23:59 UTC. Outside this window:
- Ongoing TTL jobs are canceled.
- New jobs will not be triggered until the window reopens.
How It Works:
- Before initiating a TTL job, TiDB checks if the current time falls within the configured window.
- If outside the window, all ongoing TTL jobs stop, and no new jobs begin.
Summary
By combining cron-like scheduling and configurable time windows, TiDB’s TTL feature ensures that expired data cleanup is both efficient and minimally disruptive. These mechanisms provide flexibility for balancing timely deletion with operational stability.
Next, we will examine the process of identifying and deleting expired data.
Deleting Expired Data
Removing outdated data from a table in a database can be as simple as executing a single DELETE statement. For instance, consider the following table configuration:
CREATE TABLE t (
id INT UNSIGNED PRIMARY KEY,
created_at DATETIME
) TTL = created_at + INTERVAL 10 HOUR TTL_JOB_INTERVAL = '1h';To delete records where created_at + INTERVAL 10 HOUR is earlier than a specific timestamp, you could run:
DELETE FROM t WHERE created_at + INTERVAL 10 HOUR < '2024-12-13 12:52:01.123456';However, as the size of the table grows, this direct approach presents several challenges:
- Transaction Size: A single DELETE statement might create a transaction that is too large or takes too long to execute. If it fails, the entire operation rolls back.
- Resource Impact: Deletion operations consume resources, and their speed can be hard to limit, potentially impacting other online services.
Optimizing Deletion with Batching
To address these issues, TiDB splits the deletion process into two steps:
- Querying Expired Data: Identify the records that meet the expiration criteria.
- Executing Deletions: Delete the expired records in smaller, manageable batches.
Here’s how this works in practice:
Step 1: Query in Batches
Instead of scanning the entire table in one operation, SELECT queries retrieve records in smaller chunks using a LIMIT clause. For example:
SELECT id FROM t WHERE created_at + INTERVAL 10 HOUR < '2024-12-13 12:52:01.123456' ORDER BY id ASC LIMIT 500;
SELECT id FROM t WHERE created_at + INTERVAL 10 HOUR < '2024-12-13 12:52:01.123456' AND id > x ORDER BY id ASC LIMIT 500;
SELECT id FROM t WHERE created_at + INTERVAL 10 HOUR < '2024-12-13 12:52:01.123456' AND id > y ORDER BY id ASC LIMIT 500;The batch size (e.g., 500) can be adjusted using the tidb_ttl_scan_batch_size variable. This approach ensures only a small portion of data is queried at a time, reducing the load on the system.
Step 2: Delete in Batches
Similarly, deletions are performed in chunks using IN clauses to limit the number of rows affected in each operation. For example:
DELETE FROM t WHERE id IN (id1, id2, ..., id100);
DELETE FROM t WHERE id IN (id101, id102, ..., id200);The size of these batches can be controlled through the tidb_ttl_delete_batch_size variable.
Why Batching Works
By splitting the SELECT and DELETE operations into batches:
- Each transaction is smaller and less prone to failure.
- System resources are used more efficiently, reducing the risk of performance degradation for other workloads.
- Fine-tuned control over query and deletion speed is possible through configuration.
This method ensures that even large tables with millions of records process effectively without overwhelming the database. Further details on managing flow control and resource usage will be discussed later.
Local TiDB TTL Task Scheduling
To efficiently process expired data, TiDB breaks TTL jobs into smaller subtasks that can run in parallel across the cluster. This approach ensures balanced workloads and smooth execution, even in large-scale deployments.
Breaking Down the Tasks into Subtasks
TiDB divides a table into regions, assigning each region to a subtask. This splitting ensures the workload distributes evenly across the system. For example, if a table has id values ranging from 1 to 10,000, a subtask might process only values between 128 and 999. The query for this subtask includes conditions to focus on that range:
SELECT id
FROM t
WHERE created_at + INTERVAL 10 HOUR < CURRENT_TIMESTAMP
AND id >= 128 AND id < 999
ORDER BY id ASC LIMIT 500;This targeted approach prevents redundant scanning and keeps processing efficient.
Running Subtasks in Parallel
TiDB uses two types of workers to process subtasks:
- Scan Workers query expired data in batches.
- Delete Workers remove the expired records based on the scan results.
These workers operate in parallel, with Scan Workers feeding results to Delete Workers. Multiple subtasks can run simultaneously across nodes, ensuring optimal resource usage.
Distributed Execution and Resilience
To maximize cluster resources, TiDB distributes subtasks across nodes. Subtasks are recorded in the mysql.tidb_ttl_task table, and idle nodes claim tasks to execute them.
If a node goes offline, other nodes detect the issue and take over the unfinished work, ensuring all subtasks finish reliably. This fault-tolerant design keeps the TTL process resilient and efficient.
Key Benefits
By splitting and distributing TTL tasks, TiDB achieves:
- Improved Performance: Subtasks run in parallel, reducing execution time.
- Reliable Execution: Built-in fault tolerance ensures no unfinished tasks.
- Efficient Resource Use: Nodes balance tasks, preventing bottlenecks.
This streamlined approach ensures TTL jobs process efficiently with minimal disruption to other operations.
Although such SELECT query statements are already running in batches, later ones depend on the results of previous ones and cannot be executed simultaneously. Since deletion tasks themselves don’t depend on the order of id, we might as well shard the primary keys.
Splitting Subtasks
To distribute query data volume as evenly as possible, TiDB divides the table’s regions into min(max(64, tikv count), region count) parts. Assuming each region has similar data volume, each subtask’s data volume would also be similar. The min(..., region count) part is easy to understand, as too few regions wouldn’t be enough to divide, with each subtask only getting one. max(128, tikv count) is to further improve TTL performance when the cluster is large enough.
Each subtask will contain one or more continuous regions, and the beginning and end of these regions become the scanning range for this subtask. Still using table t from above as an example, if we get a subtask with id range [128, 999), this subtask will add the condition id >= 128 AND id < 999 when running the SELECT statements described above. It becomes:
SELECT id FROM t WHERE created_at + INTERVAL 10 HOUR < '2024-12-13 12:52:01.123456' AND id >= 128 AND id < 999 ORDER BY id ASC LIMIT 500
SELECT id FROM t WHERE created_at + INTERVAL 10 HOUR < '2024-12-13 12:52:01.123456' AND id > x AND id >= 128 AND id < 999 ORDER BY id ASC LIMIT 500
SELECT id FROM t WHERE created_at + INTERVAL 10 HOUR < '2024-12-13 12:52:01.123456' AND id > y AND id >= 128 AND id < 999 ORDER BY id ASC LIMIT 500
...Multiple batches within a subtask still execute sequentially, but multiple subtasks can execute simultaneously without interfering with each other.
Mapping region beginnings and endings to SQL syntax elements (like integers, strings) isn’t easy. For example, region boundaries might not be valid utf8 strings. Currently in TiDB, there are still many limitations on this kind of splitting, so please refer to the documentation for usage restrictions.
Scan Worker and Delete Worker
Since multiple subtasks execute simultaneously, TiDB abstracts Scan Worker and Delete Worker to run these TTL subtasks. Each subtask needs to occupy a Scan Worker to run SELECT statements, sending query results to Delete Worker through a channel.

This way, TTL execution speed might be limited by several factors:
- Too few Scan Workers, with many subtasks waiting for execution.
- Too few Delete Workers, with lots of scanned expired data waiting to be deleted. This will also block Scan Workers.
- Very few subtasks, can only be deleted sequentially and slowly.
TiDB adjusts the number of Scan Workers and Delete Workers through variables tidb_ttl_scan_worker_count and tidb_ttl_delete_worker_count. They decrease to limit resources consumed by TTL functionality, or increase to speed up TTL querying and deleting expired data.
Maintaining them at reasonable values isn’t easy. Because the distribution of expired data and table width differs for each table, these two variables need to be flexibly adjusted based on actual conditions. If aiming to improve TTL speed, we can gradually adjust these two variables according to the following principles.
Observe the TTL section in the below TiDB Grafana monitoring panel. This records the proportion of Scan Workers and Delete Workers in different stages. When we find Scan Workers mostly in dispatch state (sending scanned expired data to Delete Workers) while Delete Workers rarely in idle state, as shown below, we can increase tidb_ttl_delete_worker_count.
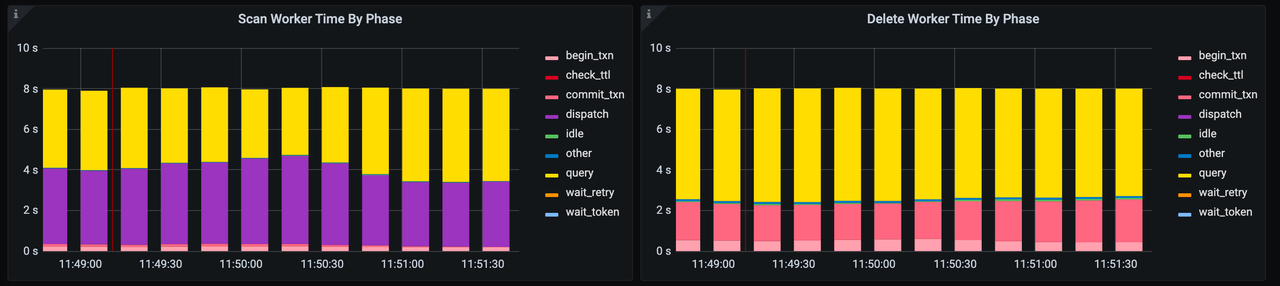
When Scan Workers are rarely in dispatch states while Delete Workers are frequently in idle states, as shown below, it indicates Scan Workers are quite busy, and we can increase tidb_ttl_scan_worker_count.

If both Scan Workers and Delete Workers are in idle state while TTL tasks run slowly, check if the corresponding TTL table meets the conditions described in the documentation for splitting into multiple subtasks.
Flow Control for DELETE Statements
In TTL, deletion (as a special type of write) consumes resources particularly noticeably. So a mechanism limits TTL functionality’s deletion speed to avoid affecting other business operations. TiDB provides a system variable tidb_ttl_delete_rate_limit to limit the number of DELETE statements executed per second by TTL functionality on a TiDB node.
This is implemented through rate.Limiter . When tidb_ttl_delete_rate_limit is non-zero, the TTL module calls rate.Limiter.Wait() before executing each DELETE statement to ensure current execution rate won’t exceed tidb_ttl_delete_rate_limit/s.
This limit is per TiDB node, regardless of multiple or single TTL tasks. If multiple TTL tasks need to run on a TiDB node, their combined deletion rate won’t exceed tidb_ttl_delete_rate_limit.
Multi-Node TiDB TTL Task Scheduling
The previous content already covers most of TTL implementation in TiDB 6.5.
Ideally, a TTL job can split into multiple subtasks running simultaneously. If all 64 subtasks execute on the same TiDB, it won’t fully utilize the entire cluster’s resources. So some improvements were made in TiDB 6.6 to distribute TTL subtasks across different TiDB nodes, getting Scan Workers and Delete Workers on each TiDB node working. This section will introduce the design of this improvement.
Subtask Scheduling
TiDB uses the mysql.tidb_ttl_task table to record subtasks split from TTL jobs. Its table structure is:
CREATE TABLE tidb_ttl_task (
job_id varchar(64) NOT NULL,
table_id bigint(64) NOT NULL,
scan_id int(11) NOT NULL,
scan_range_start blob DEFAULT NULL,
scan_range_end blob DEFAULT NULL,
expire_time timestamp NOT NULL,
owner_id varchar(64) DEFAULT NULL,
owner_addr varchar(64) DEFAULT NULL,
owner_hb_time timestamp NULL DEFAULT NULL,
status varchar(64) DEFAULT 'waiting',
status_update_time timestamp NULL DEFAULT NULL,
state textDEFAULT NULL,
created_time timestamp NOT NULL,
PRIMARY KEY (job_id,scan_id) /*T![clustered_index] NONCLUSTERED */,
KEY created_time (created_time)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_binAfter a TiDB node starts a TTL job, instead of directly starting local execution, it splits into multiple subtasks and fills them into the tidb_ttl_task table.
Similar to TTL job scheduling, each TiDB node polls this table every minute. If the current node has idle Scan Workers and there exist subtasks with empty owner_id, it will try to update that subtask’s owner_id and let the idle Scan Worker run this subtask. This way, subtasks published by any node might be discovered and run by any node. Upon completion, the Owner updates the subtask’s status to ‘finished’ to indicate a completed current subtask.
After not needing to care about TTL’s specific execution, a TTL job’s Owner has very little to do. It just needs to check its managed TTL jobs every 10 seconds to see if all corresponding subtasks are completed. If all are completed, then this TTL job successfully ends.
Note that since variable tidb_ttl_scan_worker_count controls the number of Scan Workers on each node, the cluster’s total Scan Worker count will be tidb_ttl_scan_worker_count * TiDB Count. This means if the cluster has many TiDB nodes, the number of simultaneously running TTL subtasks could be very large, consuming many resources.
Since tidb_ttl_scan_worker_count can only limit simultaneously running subtasks to integer multiples of TiDB Count, it’s inconvenient for fine-tuning. TiDB provides variable tidb_ttl_running_tasks to further limit the number of simultaneously running subtasks. It limits how many TTL subtasks can run simultaneously across the entire cluster. The range is -1 or [1,256]. -1 means the same as cluster’s TiKV node count.
Fault Tolerance
According to above design, each TTL job and subtask clearly belongs to a specific TiDB node. So if a TiDB node goes offline for various reasons, jobs and subtasks belonging to it would be unable to progress. To avoid this situation, TiDB introduced heartbeat mechanism for TTL jobs and subtasks.
Observant readers might have noticed that both mysql.tidb_ttl_table_status and mysql.tidb_ttl_task tables have a column for updating heartbeat time. For mysql.tidb_ttl_table_status this column is current_job_owner_hb_time, while for mysql.tidb_ttl_task it’s owner_hb_time.
Every 10 seconds, each TiDB node updates heartbeat time for TTL jobs it’s responsible for, and every 1 minute updates heartbeat time for TTL subtasks it’s responsible for. If the current node goes offline, heartbeat time for corresponding rows will stop updating. When other nodes find twice the specified interval has passed since heartbeat time, they can know the corresponding TTL task and subtask’s owner is in abnormal state.
TiDB nodes discovering this will try to set themselves as the job’s owner and start regularly checking for all completed subtasks; TiDB nodes discovering this and having idle Scan Workers will try to set themselves as the subtask’s owner and start querying and deleting.
TiDB TTL Configuration Items
The previous section introduced TiDB TTL’s overall design and implementation from scratch, covering all TTL-related configuration items along the way. Readers should now have a clear understanding of these variables’ origins and functions. But numerous configuration items designed to adapt to different needs can still be overwhelming. Here’s a summary:
Per-table Configuration:
- TTL_JOB_INTERVAL: Controls interval between start times of two TTL job triggers for a single table.
TTL-related Global Variables:
tidb_ttl_delete_batch_sizeandtidb_ttl_scan_batch_size: Adjust data volume for batch running SELECT and DELETE statements. Refer to “Deleting Expired Data” section above. Usually there is no need to adjust.tidb_ttl_scan_worker_countandtidb_ttl_delete_worker_count: Adjust the number of Scan Workers and Delete Workers on each TiDB node. Adjust according to “Scan Worker and Delete Worker” section above or documentation.tidb_ttl_running_tasks: Limits the number of simultaneously running TTL subtasks. Decreases when limiting TTL resource usage; increases when improving TTL performance and many restricted subtasks from scheduling to Scan Workers.tidb_ttl_delete_rate_limit: Limits total TTL deletion rate on a single TiDB node.tidb_ttl_job_schedule_window_start_timeandtidb_ttl_job_schedule_window_end_time: Limit the time window during which TTL can run in a day.
TiDB TTL Best Practices
After understanding how TiDB TTL functionality works, we can naturally summarize these best practices. Following these rules will enable better use of TTL functionality:
- For tables using clustered index, try to use integer types or strings with collation as binary / utf8mb4_bin / utf8mb4_0900_bin. Otherwise, subtasks cannot be split.
- Set reasonable
TTL_JOB_INTERVALbased on data expiration time. The ratio between the data expiration time andTTL_JOB_INTERVALshouldn’t be too large, otherwise expired data proportion in each TTL task would be very small but still needs full table scan wasting resources.
Conclusion
The current TiDB implementation of TTL still has some shortcomings, like single SELECT statement execution time quickly increasing when expired data proportion is extremely low, as it needs to scan more data (even full table) to gather 500 expired records; only tables meeting specific conditions can split subtasks (you can refer to the documentation for limitations).
As TiDB’s TTL functionality continuously improves, we look forward to hearing from users like you how we can make it even better. Please feel free to drop us a line with your feedback on Twitter, LinkedIn, or through our Slack Channel.
Experience modern data infrastructure firsthand.
Related Resources

Customer Story
Scaling Beyond Limits: How EasyPost Future-Proofed Its Infrastructure with Distributed SQL

Product
Secure by Design: How TiDB Cloud Protects Your Data and Simplifies Compliance

Engineering
Optimizing Backup Verification: How to Enhance Performance and Reliability in TiDB
TiDB Cloud Dedicated
A fully-managed cloud DBaaS for predictable workloads
TiDB Cloud Serverless
A fully-managed cloud DBaaS for auto-scaling workloads