
Authors: Ghimsim Chua (Product Manager of TiDB Cloud); Siddon Tang (VP of Engineering at PingCAP)
Editors: Fendy Feng, Tom Dewan, Rick Golba
I recently had coffee with a potential customer, and we started discussing TiDB’s Hybrid Transactional and Analytical Processing (HTAP) capabilities. He was skeptical that HTAP had much practical use, saying that TiDB’s optimal boundary size limit of 500 TB and slower performance than dedicated data warehouses like Snowflake or Databricks would limit its usefulness. I had my laptop, so I decided to give him a quick demo. I entered an analytic query. Just as I hit “Return,” I asked him, “How long do you think this query will take to run on 4 billion rows of data on TiDB?” He responded, “At least 2 minutes.” But as he said this, TiDB returned the results.
He was stumped.
I explained to him that TiDB’s analytic queries may be a second or two slower than Snowflake or Databricks, but if you consider the overall time that it takes to load the data into the warehouses before you can query it, it might be significantly longer than using a HTAP database. Furthermore, the data that you are querying will not be the most up-to-date. It may be hours or even days old. With TiDB, you operate on data that is being ingested into the database in real time.”
That conversation got me thinking: what are the true benefits of HTAP? How can customers harness the power of distributed HTAP databases like TiDB? Which use cases are more suitable for HTAP databases than data warehouses?
>> Download the White Paper: Enabling Data Agility with an HTAP Database <<
Simplifying the architecture
Many e-commerce, AdTech, or logistics applications store incoming transactions in an Online Transactional Processing (OLTP) or NoSQL database. This is because applications need a System of Record for the transactions. However, when analytical queries or reports need to be generated, the data must be shipped to a data warehouse for further processing because OLTP or NoSQL databases are far too slow for analytical tasks. This is typically done with an extract, transform, load (ETL) pipeline, which first loads all the data from the transactional database and then updates the data in the warehouse as new transactions come in.
This architecture has several downsides. First, if the dataset is huge, loading it can take a long time. Analytical queries may perform faster in a data warehouse, but you may have to wait for all the data to complete loading. Otherwise, you would be operating on out-of-date data. Second, with additional processes like the ETL and data warehouse to run, there will be more systems for the infra or operations team to monitor and manage. More processes also increase the odds of failure in any of these components. More processes also consume more resources, which increases the resource usage costs.

The typical workflow of a traditional OLTP or NoSQL database
In an architecture using a distributed HTAP database like TiDB, a single TiDB cluster can replace the transactional database, ETL pipeline, and data warehouse. Since the data is safely and automatically replicated in both row and column stores, you don’t need another ETL pipeline or a data warehouse. This reduces resource usage, and operation and maintenance costs. Fewer components also significantly reduces the chance of failure.

A simplified architecture of TiDB
Reducing the data stack
Distributed HTAP databases also remove the need for many analytical processes like Kafka, message queues, and data caches.
In a traditional data stack architecture like the one shown below, different applications write data into a relational database like MySQL or PostgreSQL. Then, a stream processor like Kafka, Pulsar, or Message Q transfers the data to Spark, Flink, or Hive for additional processing. Finally, the processed data is saved into a cache like Redis, to be served later when needed. This architecture works, but is rather complex.

The traditional data stack architecture
In contrast, an HTAP database like TiDB drastically simplifies the data stack.
First, TiDB processes the data directly inside the database using its analytical capabilities. It doesn’t need to transfer the data for outside processing. This avoids significant network latency and possible data transfer costs.
Second, TiDB creates a simple table to store the processed data. There’s no need to ship the result to a cache like Redis for temporary storage. TiDB has a distributed, scalable architecture, and it can act as the database store as well as the cache. This approach significantly reduces operational and infrastructure costs and cuts the risk of component failure.
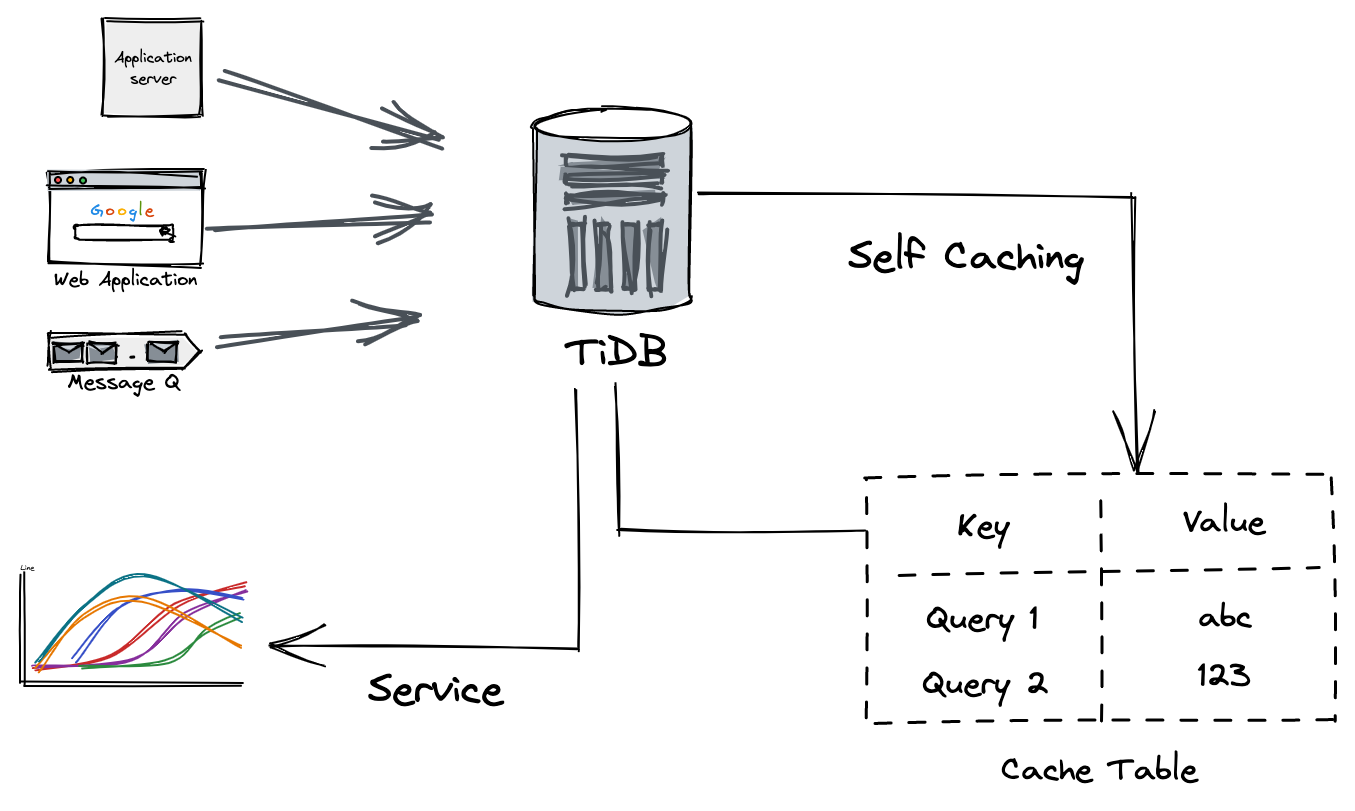
The simplified data stack architecture in TiDB
Leveraging HTAP’s query optimizer
HTAP databases like TiDB that store data in both row and column stores have a unique advantage: the query optimizer has a choice of query plans that can use either row or column stores. It can then intelligently pick the plan that returns the results the fastest. Traditional Online Analytical Processing (OLAP) or OLTP databases do not have this option. They only have one type of storage.
As shown in the figure below, three different queries leverage different data stores in TiDB.
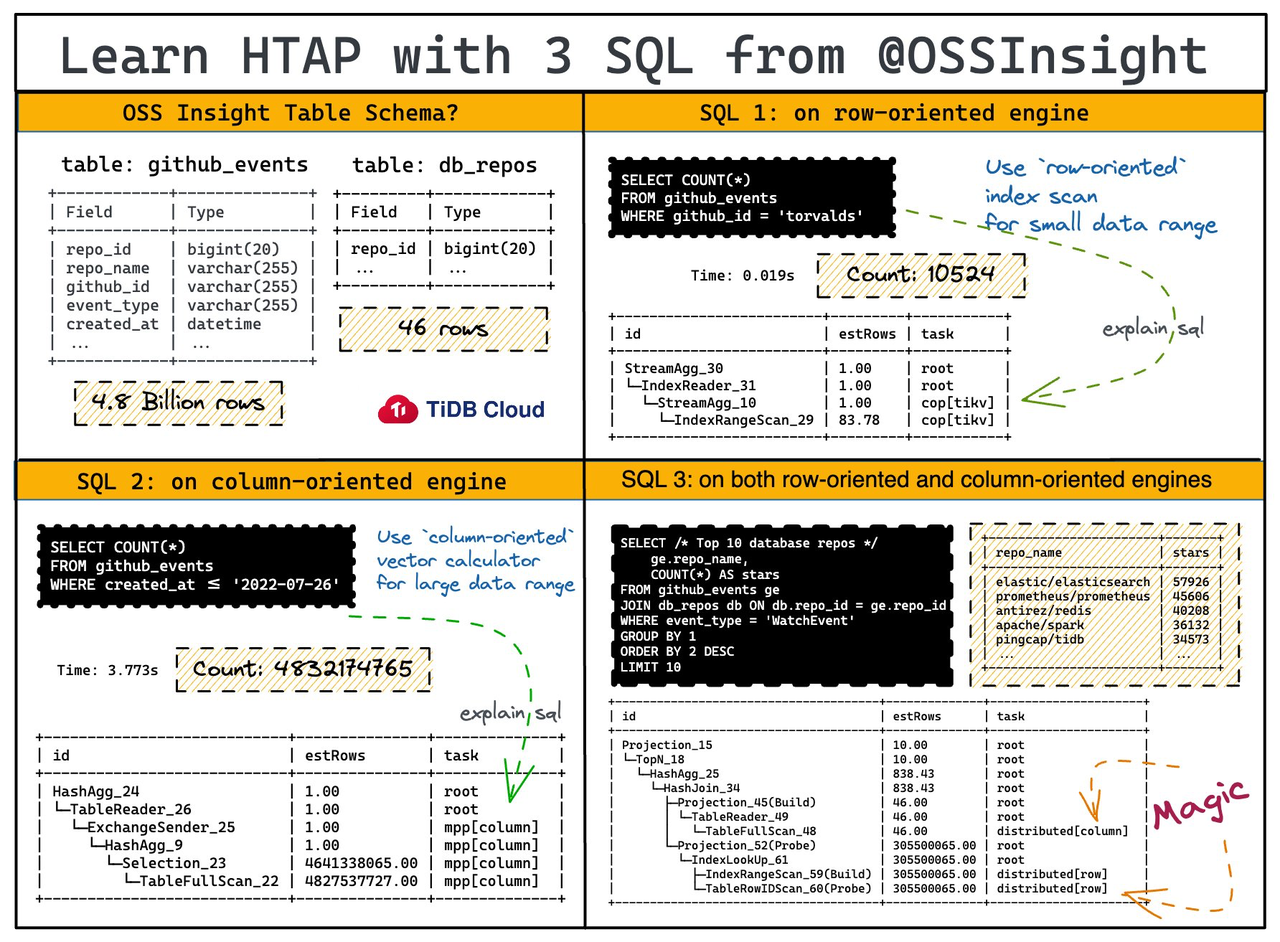
In SQL 1, the optimizer chooses the row store. This is because the query only spans a small data range, and it can use an index scan to efficiently locate all the rows which satisfy the WHERE condition. SQL 2 uses the column store. The data range is large, and it can be more efficiently computed by the analytical engine. Lastly, in SQL3, the query can be split and processed by both the column and row stores. The inner query has a small data range, while the outer query has a much larger data range to scan.
This use case proves that you can focus on your business logic and not worry about where you need to store the data to execute your queries.
Wrapping up
There are use cases where HTAP databases cannot yet replace the data warehouse entirely. In the case of TiDB, the 500 TB limit and high cost of storing all data as “hot” limit its applicability to use cases that fall within those limits. Our engineers are working hard to overcome these limits, but meanwhile, I strongly believe that there are still a lot of use cases for HTAP databases like TiDB to solve.
Keep reading:
Real-World HTAP: A Look at TiDB and SingleStore and Their Architectures
The Beauty of HTAP: TiDB and AlloyDB as Examples
The Long Expedition toward Making a Real-Time HTAP Database
Experience modern data infrastructure firsthand.



TiDB Cloud Dedicated
A fully-managed cloud DBaaS for predictable workloads
TiDB Cloud Serverless
A fully-managed cloud DBaaS for auto-scaling workloads