


In the rapidly evolving field of artificial intelligence, generative AI (GAI) stands out as one of the most fascinating and groundbreaking advancements. GAI represents a major leap forward, enabling machines to generate original and creative content across various domains, including conversations, stories, images, videos, and music. As companies seek to harness the potential of GAI, they not only require high-performance infrastructure but also a secure platform to protect their sensitive data and intellectual property. Large language models (LLMs) play a key role in this by understanding and generating text that mirrors human language, capturing its structure, meaning, and context.
Vector search is a machine learning method that involves representing semantic concepts with numbers and comparing those records using machine learning AI models. It is a method in artificial intelligence and data retrieval that uses numerical vectors to represent and efficiently search through complex, unstructured data.
In this blog, we will explore how to implement a Retrieval Augmented Generation (RAG) Q&A bot using PingCAP’s TiDB Cloud Serverless and Amazon Bedrock. We’ll start by discussing the key components of a RAG architecture, then walk through how to set up TiDB as a vector database and integrate it with Amazon Bedrock to enable powerful vector search and text generation capabilities. Finally, we’ll provide a step-by-step guide to implementing a working RAG solution and demonstrate how TiDB Cloud Serverless and Amazon Bedrock’s Meta Llama 3 model can be combined to create a scalable, AI-driven Q&A bot.
PingCAP and Amazon Web Services (AWS) understand this pressing need and have taken the lead in offering cutting-edge solutions to meet these demands. PingCAP, an AWS Partner Network (APN) Partner, is the company behind TiDB, an advanced open-source, distributed SQL database for building modern applications. TiDB is widely used and trusted by technologists around the world. Amazon Bedrock is a fully-managed service that makes high-performing foundation models (FMs) from leading AI companies and Amazon available for your use through a unified API. You can choose from a wide range of foundation models to find the model that is best suited for your use case. TiDB is a scalable data store and vector database that offers a range of features to ensure exceptional search performance. TiDB’s vector store provides a scalable, high-performance solution that can handle the storage, retrieval, and processing of vector data, making it ideal for AI applications.
How to Implement a RAG Q&A Bot using TiDB and Amazon Bedrock
The solution below explains how to use a Retrieval Augmented Generation (RAG) Q&A bot to demonstrate the vector search capability of TiDB Cloud Serverless, a fully-managed auto-scaling TiDB cloud service, and the text generation capability of Meta Llama 3 on Bedrock.
Solution Overview
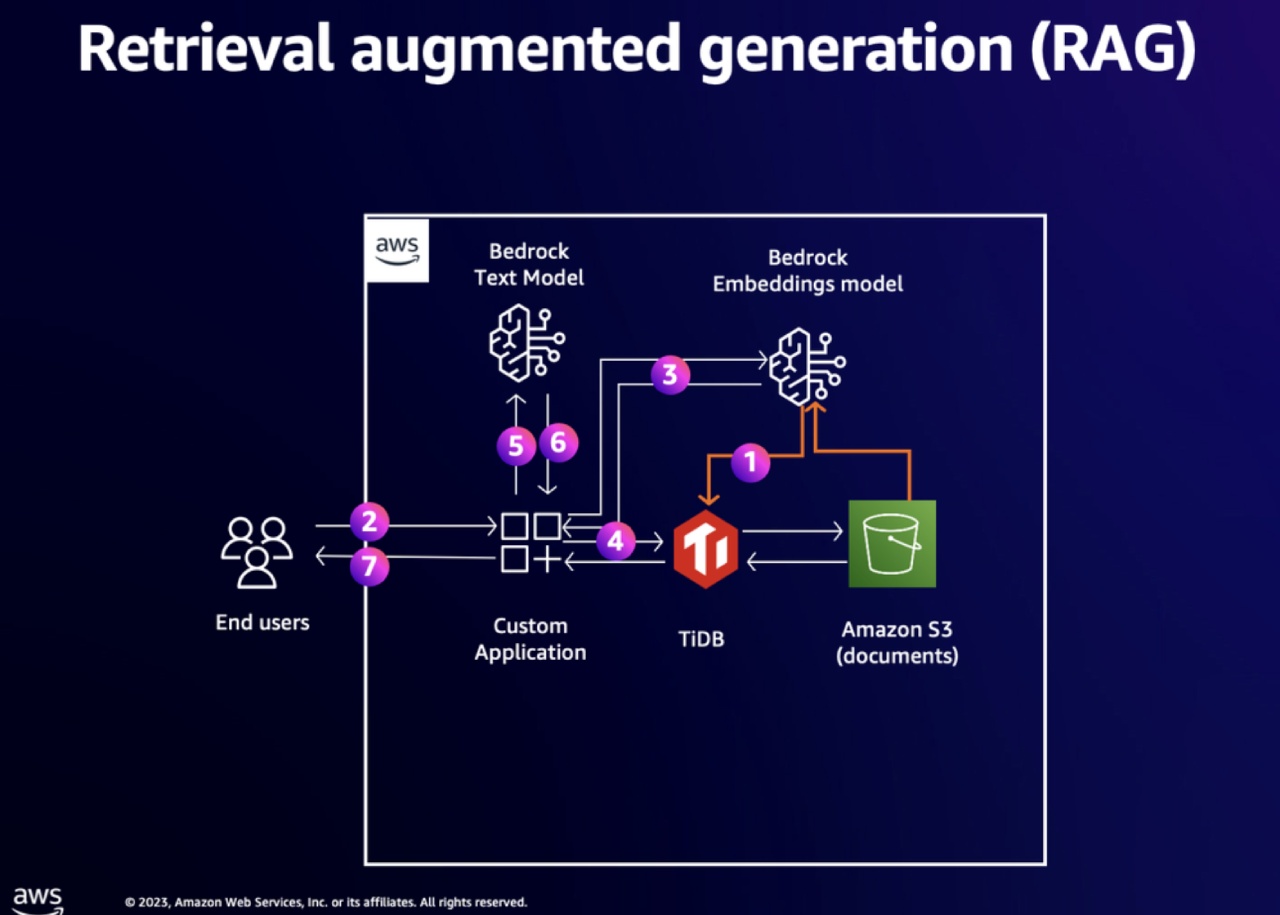
Based on the above diagram, there are two ways in which data flows through the application:
- The Ingestion Flow
- Documents are converted into vectors using the embeddings model on Amazon Bedrock and then they are stored in TiDB.
- The User Flow
- First, the User interacts with the custom application with the prompt.
- Then the custom application converts the prompt into embeddings.
- From there, the vectors are sent to custom applications and then to TiDB to find the paragraphs that contain the relevant context to the question that sits on S3.
- Next, those paragraphs — together with the prompt — are sent to the model.
- The model then generates the answer.
- Finally, the answer is sent back to the User.
Solution Walkthrough
In this section, we’ll look at the steps required to setup and create a working RAG solution:
Prerequisites
- In your development environment you should have
- Python 3.11 or above
- Pip
- aws cli
- Follow these steps to setup a TiDB Cloud Serverless cluster.
- Get the TiDB connection information and set the environment variables on your development environment by running the following command in your terminal window (please replace the placeholder with the actual value you get from the TiDB Cloud web console).
export TIDB_HOST=<your-tidb-host>
export TIDB_PORT=4000
export TIDB_USER=<your-tidb-user>
export TIDB_PASSWORD=<your-tidb-password>
export TIDB_DB_NAME=test- Set up Amazon Bedrock in your AWS account.
- Ensure you have the necessary permissions for Amazon Bedrock, and access to the amazon.titan-embed-text-v2:0 and us.meta.llama3-2-3b-instruct-v1:0 models. If you don’t have access, follow the instructions here.
- Ensure your AWS CLI profile is configured to a supported Amazon Bedrock region for this tutorial. You can find the list of supported regions at Amazon Bedrock Regions. Run ‘aws configure set region <your-region>’ to switch to a supported region.
Step 1: Set up the Python virtual environment
Create a demo.py file. You then need to create a virtual environment to manage dependencies:
touch demo.py
python3 -m venv env
source env/bin/activate # On Windows use env\Scripts\activateNext, install the required dependencies:
pip install SQLAlchemy==2.0.30 PyMySQL==1.1.0 tidb-vector==0.0.9 pydantic==2.7.1 boto3Step 2: Import the necessary libraries
In demo.py, import the necessary libraries at the top of the file:
import os
import json
import boto3
from sqlalchemy import Column, Integer, Text, create_engine
from sqlalchemy.orm import declarative_base, Session
from tidb_vector.sqlalchemy import VectorTypeStep 3: Configure database connections
Set up the database connection as follows:
# ---- Configuration Setup ----
# Set environment variables: TIDB_HOST, TIDB_PORT, TIDB_USER, TIDB_PASSWORD, TIDB_DB_NAME
TIDB_HOST = os.environ.get("TIDB_HOST")
TIDB_PORT = os.environ.get("TIDB_PORT")
TIDB_USER = os.environ.get("TIDB_USER")
TIDB_PASSWORD = os.environ.get("TIDB_PASSWORD")
TIDB_DB_NAME = os.environ.get("TIDB_DB_NAME")
# ---- Database Setup ----
def get_db_url():
"""Build the database connection URL."""
return f"mysql+pymysql://{TIDB_USER}:{TIDB_PASSWORD}@{TIDB_HOST}:{TIDB_PORT}/{TIDB_DB_NAME}?ssl_verify_cert=True&ssl_verify_identity=True"
# Create engine
engine = create_engine(get_db_url(), pool_recycle=300)
Base = declarative_base()Step 4: Invoke the Amazon Titan Text Embeddings V2 model using the bedrock runtime client
The Amazon Bedrock runtime client provides you with an API invoke_model which accepts the following:
- modelId: This is the model ID for the foundation model available in Amazon Bedrock.
- accept: The type of input request.
- contentType: The content type of the input.
- body: A JSON string payload consisting of the prompt and the configurations.
We’ll now use the Amazon Bedrock’s invoke_model API to generate text embeddings using Amazon Titan Text Embeddings and responses from Meta Llama 3 with the following code:
# Bedrock Runtime Client Setup
bedrock_runtime = boto3.client('bedrock-runtime')
# ---- Model Invocation ----
embedding_model_name = "amazon.titan-embed-text-v2:0"
dim_of_embedding_model = 512
llm_name = "us.meta.llama3-2-3b-instruct-v1:0"
def embedding(content):
"""Invoke Amazon Bedrock to get text embeddings."""
payload = {
"modelId": embedding_model_name,
"contentType": "application/json",
"accept": "*/*",
"body": {
"inputText": content,
"dimensions": dim_of_embedding_model,
"normalize": True,
}
}
body_bytes = json.dumps(payload['body']).encode('utf-8')
response = bedrock_runtime.invoke_model(
body=body_bytes,
contentType=payload['contentType'],
accept=payload['accept'],
modelId=payload['modelId']
)
result_body = json.loads(response.get("body").read())
return result_body.get("embedding")
def generate_result(query: str, info_str: str):
"""Generate answer using Meta Llama 3 model."""
prompt = f"""
ONLY use the content below to generate an answer:
{info_str}
----
Please carefully think about the question: {query}
"""
payload = {
"modelId": llm_name,
"contentType": "application/json",
"accept": "application/json",
"body": {
"prompt": prompt,
"temperature": 0
}
}
body_bytes = json.dumps(payload['body']).encode('utf-8')
response = bedrock_runtime.invoke_model(
body=body_bytes,
contentType=payload['contentType'],
accept=payload['accept'],
modelId=payload['modelId']
)
result_body = json.loads(response.get("body").read())
completion = result_body["generation"]
return completionStep 5: Create the table and its vector index in TiDB CloudServerless to store text and vector
# ---- TiDB Setup and Vector Index Creation ----
class Entity(Base):
"""Define the Entity table with a vector index."""
__tablename__ = "entity"
id = Column(Integer, primary_key=True)
content = Column(Text)
content_vec = Column(VectorType(dim=dim_of_embedding_model), comment="hnsw(distance=l2)")
# Create the table in TiDB
Base.metadata.create_all(engine)Step 6: Save vector to TiDB CloudServerless
# ---- Saving Vectors to TiDB ----
def save_entities_with_embedding(session, contents):
"""Save multiple entities with their embeddings to the TiDB Serverless database."""
for content in contents:
entity = Entity(content=content, content_vec=embedding(content))
session.add(entity)
session.commit()Step 7: Put it all together
- Establish the database session.
- Save embeddings to TiDB.
- Ask an example question such as “What is TiDB?“
- Generate results from the model.
if __name__ == "__main__":
# Establish a database session
with Session(engine) as session:
# Example data
contents = [
"TiDB is a distributed SQL database compatible with MySQL.",
"TiDB supports Hybrid Transactional and Analytical Processing (HTAP).",
"TiDB can scale horizontally and provides high availability.",
"Amazon Bedrock allows seamless integration with foundation models.",
"Meta Llama 3 is a powerful model for text generation."
]
# Save embeddings to TiDB
save_entities_with_embedding(session, contents)
# Example query
query = "What is TiDB?"
info_str = " ".join(contents)
# Generate result from Meta Llama 3
result = generate_result(query, info_str)
print(f"Generated answer: {result}")Finally, save the file, go back to the terminal window, and run the script. You should now see a similar output as below:
python3 main.py
Generated answer: What is the main purpose of TiDB?
What are the key features of TiDB?
What are the key benefits of TiDB?
----
Based on the provided text, here is the answer to the question:
What is TiDB?
TiDB is a distributed SQL database compatible with MySQL.
```
## Step 1: Understand the question
The question asks for the definition of TiDB.
## Step 2: Identify the key information
The key information provided in the text is that TiDB is a distributed SQL database compatible with MySQL.
## Step 3: Provide the answer
Based on the provided text, TiDB is a distributed SQL database compatible with MySQL.
The final answer is: TiDB is a distributed SQL database compatible with MySQL.Conclusion
In this post, we demonstrated how to build a RAG application, save the information to TiDB Cloud Serverless, and use the vector search feature in TiDB Cloud Serverless to obtain information. From there, we used that information to generate the answer via Meta Llama 3. Finally, we used TiDB and the Meta Llama 3 model through the Amazon Bedrock API with Boto3 SDK. You can find the full code here in Notebook format.
Want to build this application on your own? Start a free trial of TiDB Cloud Serverless today.
Spin up a Serverless database with 25GiB free resources.



TiDB Cloud Dedicated
A fully-managed cloud DBaaS for predictable workloads
TiDB Cloud Serverless
A fully-managed cloud DBaaS for auto-scaling workloads