
Author: Qiang Wu (TiDB Cloud Engineer at PingCAP)
Editors: Calvin Weng, Tom Dewan
TiDB Cloud is a fully-managed Database-as-a-Service (DBaaS) for TiDB, an open source distributed SQL database.
Databricks is a web-based data analytics platform that works with Spark. It combines the best of data warehouses and data lakes into a lake-house architecture.
With a built-in JDBC driver in Databricks, you can now connect TiDB Cloud to Databricks in a few minutes and use Databricks to analyze the data in TiDB. In this article, we will walk you through how to create a TiDB Cloud Developer Tier cluster, connect TiDB to Databricks, and process TiDB data with Databricks.
Set up your TiDB Cloud Dev Tier cluster
To get started with TiDB Cloud, do the following:
- Sign up for a TiDB Cloud account and log in.
- Under Create Cluster > Developer Tier, select 1 year Free Trial.
- Set your cluster name and choose the region for your cluster.
- Click Create. A TiDB Cloud cluster will be created in approximately 1 to 3 minutes.
- In the Overview panel, click Connect and create the traffic filter. Here we add an IP address of 0.0.0.0/0 to allow access from any other IPs.
- Take note of your JDBC URL, which you will use later in Databricks.
Import sample data to TiDB Cloud
After you create a cluster, it’s time to migrate the sample data to TiDB Cloud. For demonstration purposes, we will use a sample system dataset from Capital Bikeshare, a bicycle-sharing platform. The sample data is released under the Capital Bikeshare Data License Agreement.
- In the cluster information pane, click Import. The Data Import Task page is displayed.
- Configure the import task as follows:
- Data Source Type:
Amazon S3 - Bucket URL:
s3://tidbcloud-samples/data-ingestion/ - Data Format:
TiDB Dumpling - Role-ARN:
arn:aws:iam::385595570414:role/import-sample-access
- Data Source Type:
- For Target Database, enter the Username and Password of the TiDB cluster.
- To start importing the sample data, click Import. The process takes about 3 minutes.
- Return to the overview panel and click Connect to Get the MyCLI URL.
- Use the MyCLI client to check your sample data import:
$ mycli -u root -h tidb.xxxxxx.aws.tidbcloud.com -P 4000(none)> SELECT COUNT(*) FROM bikeshare.trips;+----------+| COUNT(*) |+----------+| 816090 |+----------+1 row in setTime: 0.786s
Connect to TiDB Cloud on Databricks
Before you continue, make sure you have logged into your workspace on Databricks with your own account. If you don’t have a Databricks account, sign up for a free one here. If you are an experienced Databricks user and want to import the notebook directly, you can skip to (Optional) Import the TiDB Cloud example notebook to Databricks.
In this section, we will create a new notebook on Databricks, attach it to a Spark cluster, and then use the JDBC URL to connect it to TiDB Cloud.
- In the Databricks workspace, create and attach a Spark cluster as shown below:

- Configure JDBC in the Databricks notebook. TiDB can use the default JDBC driver in Databricks, so we don’t need to configure the driver parameter:
%scala val url = "jdbc:mysql://tidb.xxxx.prod.aws.tidbcloud.com:4000" val table = "bikeshare.trips" val user = "root" val password = "xxxxxxxxxx"where
url: JDBC URL used to connect to TiDB Cloud
table: Specify the table, such as ${database}.${table}
user: The username to use to connect to TiDB Cloud
password: The password of the user - Check the connectivity to TiDB Cloud:
%scala import java.sql.DriverManager val connection = DriverManager.getConnection(url, user, password) connection.isClosed() res2: Boolean = false
Analyze your data in Databricks
Once the connection is established, you can load TiDB data as a Spark DataFrame and analyze the data in Databricks.
- Load TiDB data by creating a DataFrame for Spark. Here we will reference the variables we defined in the previous step:
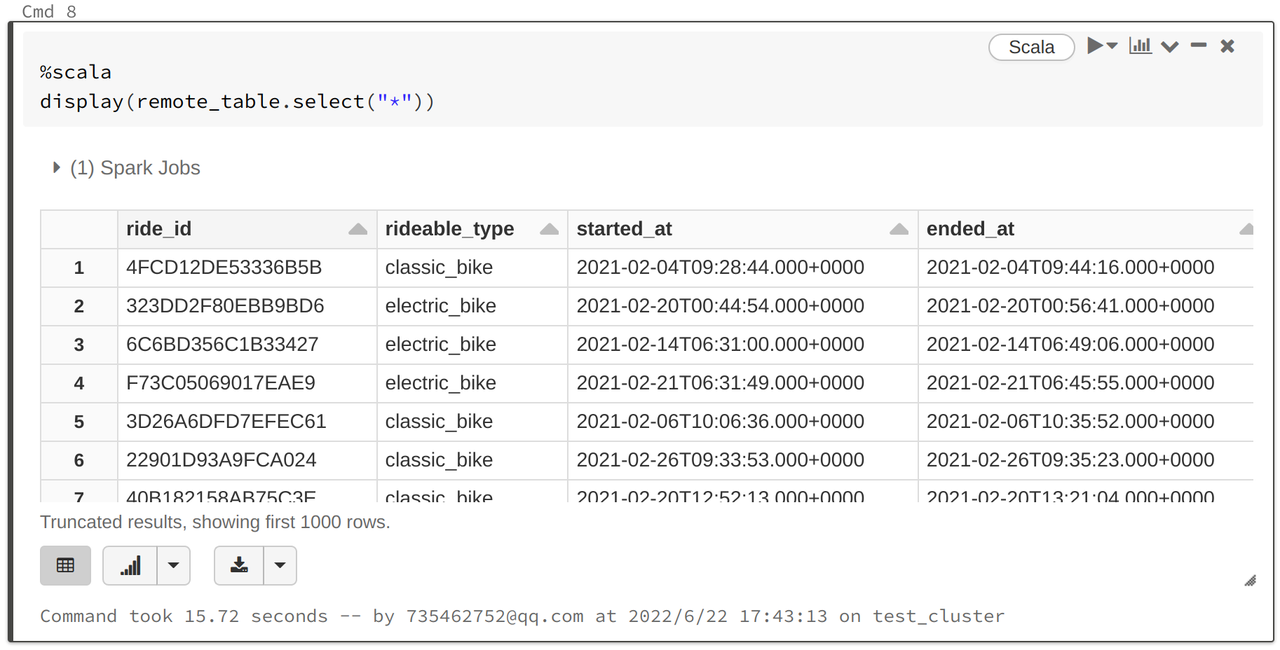
%scala val remote_table = spark.read.format("jdbc") .option("url", url) .option("dbtable", table) .option("user", user) .option("password", password) .load() - Query the data. Databricks provides a powerful chart display function that customizes the type of chart you want:
%scala display(remote_table.select("*"))
- Create a view or a table for the DataFrame. In our example, we create a temporary view named “trips”:
%scala remote_table.createOrReplaceTempView("trips") - Query the data using SQL statements. The following statement will query the count of bikes per type:
%sql SELECT rideable_type, COUNT(*) count FROM trips GROUP BY rideable_type ORDER BY count DESC - Write the analytic results to TiDB Cloud:
%scala spark.table("type_count") .withColumnRenamed("type", "count") .write .format("jdbc") .option("url", url) .option("dbtable", "bikeshare.type_count") .option("user", user) .option("password", password) .option("isolationLevel", "NONE") .mode(SaveMode.Append) .save()
(Optional) Import the TiDB Cloud example notebook to Databricks
This is a TiDB Cloud sample notebook that contains steps of Connect to TiDB Cloud on Databricks and Analyze your TiDB data in Databricks. You can import this directly to focus more on the analytic process.
- In your Databricks workstation, click Create > Import and paste TiDB Cloud example URL to download a notebook to your own Databricks workspace.
- Attach this notebook to your Spark cluster.
- Replace the JDBC configurations of the example with your own TiDB Cloud cluster.
- Follow the steps in the notebook and try TiDB cloud with Databricks.
Conclusion
This article shows how to use TiDB Cloud with Databricks. You can click here to try TiDB Cloud now in just a few minutes. In the meantime, we are working on another tutorial about how to connect TiDB from Databricks via TiSpark, a thin query layer built for running Apache Spark on top of TiDB/TiKV. Subscribe to our blog to stay tuned.
Keep reading:
Using Airbyte to Migrate Data from TiDB Cloud to Snowflake
How to Achieve High-Performance Data Ingestion to TiDB in Apache Flink
Data Transformation on TiDB Made Easier
Want to explore TiDB without installing any software? Go to TiDB Playground
Spin up a Serverless database with 25GiB free resources.
Related Resources

Product
Secure by Design: How TiDB Cloud Protects Your Data and Simplifies Compliance

Product
Node Groups in TiDB Cloud: The Key to Scaling Workloads with Predictable Performance and Control

Product
TiDB Cloud CONNECTED Care: Elevate Your Support with Seamless, Real-Time Connectivity
TiDB Cloud Dedicated
A fully-managed cloud DBaaS for predictable workloads
TiDB Cloud Serverless
A fully-managed cloud DBaaS for auto-scaling workloads