
This is the speech Siddon Tang gave at the 1st Rust Meetup in Beijing on April 16, 2017.
Hello everyone, today I will talk about how we use Rust in TiKV.
Before we begin, let me introduce myself. My name is Siddon Tang, the Chief Architect of PingCAP. Before I joined PingCAP, I had worked at Kingsoft and Tencent. I love open source and have developed some projects like LedisDB, go-mysql, etc…
At first, I will explain the reason why we chose Rust to develop TiKV, then show you the architecture of TiKV briefly and the key technologies. In the end, I will introduce what we plan to do in the future.
What’s TiKV?
All right, let’s begin. First, what is TiKV. TiKV is a distributed Key-Value database with the following features:
- Geo-replication: We use Raft and Placement Driver to replicate data geographically to guarantee data safety.
- Horizontal scalability: We can add some nodes directly if we find that the rapidly growing data will soon exceed the system capacity.
- Consistent distributed transaction: We use an optimized, two phase commit protocol, based on Google Percolator, to support distributed transactions. You can use “begin” to start a transaction, then do something, then use “commit” or “rollback” to finish the transaction.
- Coprocessor for distributed computing: Just like HBase, we support a coprocessor framework to let user do computing in TiKV directly.
- Working with TiDB like Spanner with F1: Using TiKV as a backend storage engine of TiDB, we can provide the best distributed relational database.
We need a language with…
As you see, TiKV has many powerful features. To develop these features, we also need a powerful programming language. The language should have:
- Fast speed: We take the performance of TiKV very seriously, so we need a language which runs very fast at runtime.
- Memory safety: As a program that is going to run for a long time, we don’t want to meet any memory problem, such as dangling pointer, memory leak, etc…
- Thread safety: We must guarantee data consistency all the time, so any data race problem must be avoided.
- Binding C efficiency: We depend on RocksDB heavily, so we must be able to call the RocksDB API as fast as we can, without any performance reduction.
Why not C++?
To develop a high performance service, C++ may be the best choice in most cases, but we didn’t choose it. We figured we might spend too much time avoiding the memory problem or the data race problem. Moreover, C++ has no official package manager and that makes the maintaining and compiling third dependences very troublesome and difficult, resulting in a long development cycle.
Why not Go?
At first, we considered using Go, but then gave up this idea. Go has GC which fixes many memory problems, but it might stop the running process sometimes. No matter how little time the stop takes, we can’t afford it. Go doesn’t solve the data race problem either. Even we can use double dash race in test or at runtime, this isn’t enough.
Besides, although we can use Goroutine to write the concurrent logic easily, we still can’t neglect the runtime expenses of the scheduler. We met a problem a few days ago: we used multi goroutines to select the same context but found that the performance was terrible, so we had to use one sub context for one goroutine, then the performance became better.
More seriously, CGO has heavy expenses, but we need to call RocksDB API without delay. For the above reasons, we didn’t choose Go even this is the favorite language in our team.
So we turned to Rust…
But Rust…
Rust is a system programming language, maintained by Mozilla. It is a very powerful language, however, you can see the curve, the learning curve is very very steep.
I have been using many programming languages, like C++, Go, python, lua, etc. and Rust is the hardest language for me to master. In PingCAP, we will let the new colleague spend at least one month to learn Rust, to struggle with the compiling errors, and then to rise above it. This would never happen for Go.
Besides, the compiling time is very long, even longer than C++. Each time when I type cargo build to start building TiKV, I can even do some pushups.
Although Rust is around for a long time, it still lacks of libraries and tools, and some third projects have not been verified in production yet. These are all the risks for us. Most seriously, it is hard for us to find Rust programmer because only few know it in China, so we are always shorthanded.
Then, Why Rust?
Although Rust has the above disadvantages, its advantages are attractive for us too. Rust is memory safe, so we don’t need to worry about memory leak, or dangling pointer any more.
Rust is thread safe, so there won’t be any data race problem. All the safety are guaranteed by compiler. So in most cases, when the compiling passes, we are sure that we can run the program safely.
Rust has no GC expenses, so we won’t meet the “stop the world” problem. Calling C through FFI is very fast, so we don’t worry the performance reduction when calling the RocksDB API. At last, Rust has an official package manager, Cargo, we can find many libraries and use them directly.
We made a hard but great decision: Use Rust!
TiKV Timeline
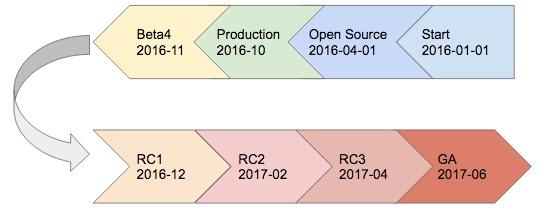
Here you can see the TiKV timeline. We first began to develop TiKV January 1st, 2016, and made it open source on April 1st, 2016, and this is not a joke like Gmail at All April Fool’s Day. TiKV was first used in production in October, 2016, when we had not even released a beta version. In November, 2016, we released the first beta version; then RC1 in December, 2016, RC2 in February, this year. Later we plan to release RC3 in April and the first GA version in June.
As you can see, the development of TiKV is very fast and the released versions of TiKV are stable. Choosing Rust has already been proved a correct decision. Thanks, Rust.
TiKV Architecture
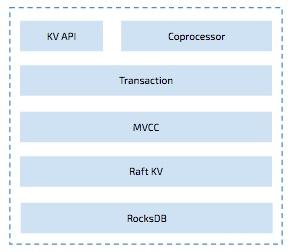
Now let’s go deep into TiKV. You can see from the TiKV architecture that the hierarchy of TiKV is clear and easy to understand.
At the bottom layer, TiKV uses RocksDB, a high performance, persistent Key-Value store, as the backend storage engine.
The next layer is Raft KV. TiKV uses the Raft to replicate data geographically. TiKV is designed to store tons of data which one Raft group can’t hold. So we split the data with ranges and use each range as an individual Raft group. We name this approach: Multi-Raft groups.
TiKV provides a simple Key-Value API including SET, GET, DELETE to let user use it just as any distributed Key-Value storage. The upper layer also uses these to support advanced functions.
Above the Raft layer, it is MVCC. All the keys saved in TiKV must contain a globally unique timestamp, which is allocated by Placement Driver. TiKV uses it to support distributed transactions.
On the top layer, it is the KV and coprocessor API layer for handling client requests.
Multi-Raft
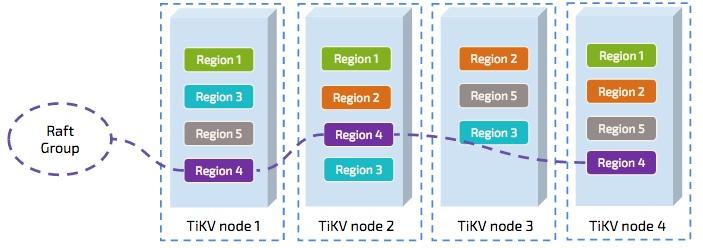
Here is an example of Multi-Raft.
You can see that there are four TiKV nodes. Within each store, we have several regions. Region is the basic unit of data movement and is replicated by Raft. Each region is replicated to three nodes. These three replicas of one Region make a Raft group.
Scale Out
Scale-out (initial state)
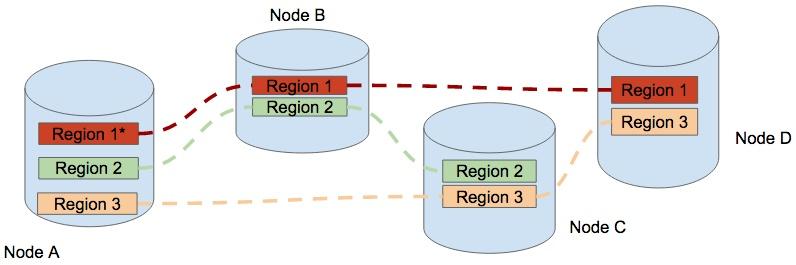
Here is an example of horizontal scalability. At first, we have four nodes, Node A has three regions, others have two regions.
Of course, Node A is busier than other nodes, and we want to reduce its stress.
Scale-out (add new node)
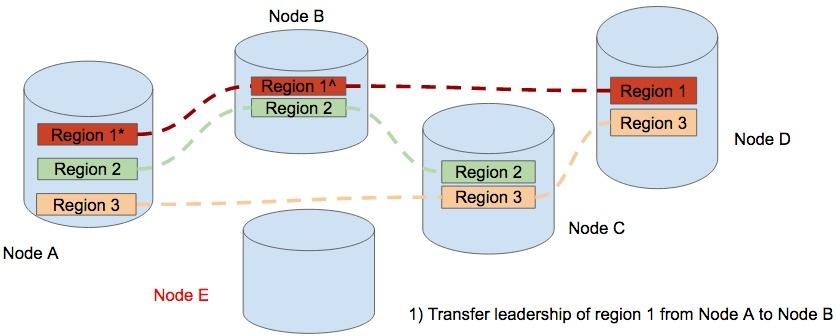
So we add a new Node E, and begin to move the region 1 in Node A to Node E. But here we find that the leader of region 1 is in Node A, so we will first transfer the leader from Node A to Node B.
Scale-out (balancing)
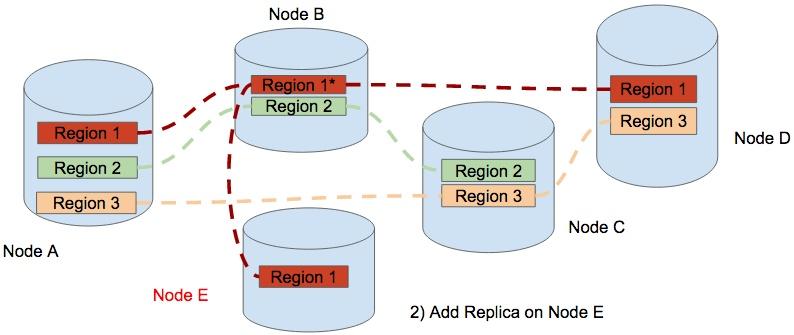
After that, the leader of region 1 is in Node B now, then we add a new replica of region 1 in Node E.
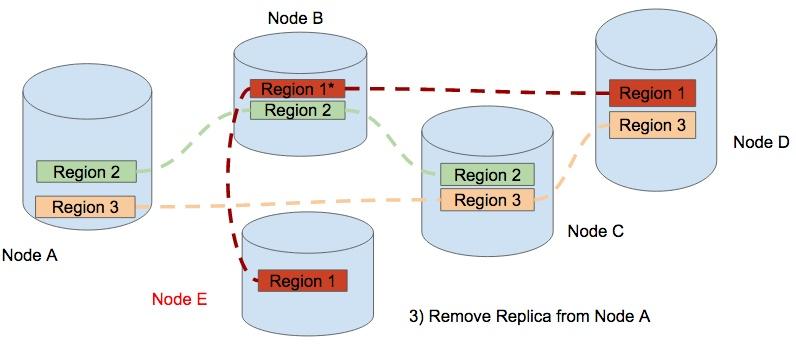
Then we remove the replica of region 1 from Node A. All these are executed by the Placement Driver automatically. What we only need is to add node, if we find the system is busy. Very easy, right?
A simple write flow
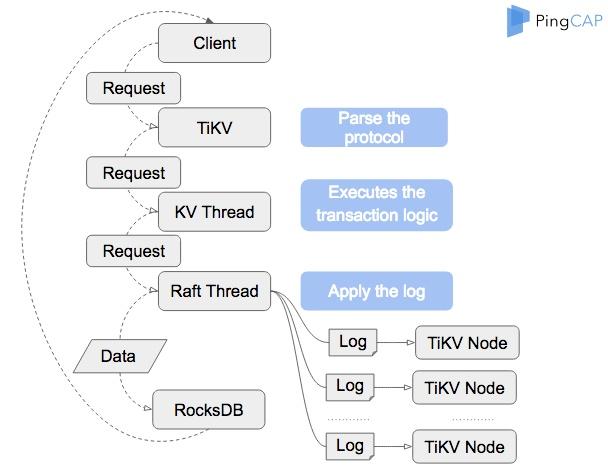
Here is a simple write flow: when a client sends a write request to TiKV, TiKV first parses the protocol and then dispatches the request to the KV thread, then the KV thread executes some transaction logics and sends the request to Raft thread, after TiKV replicates the Raft log and applies it to RocksDB, the write request is finished.
Key technologies
Now let’s move on to the key technologies:
For networking, we use a widely used protocol, Protocol Buffers, to serialize or unserialize data fastly.
At first, we used MIO to build up the network framework. Although MIO encapsulates low level network handling, it is still a very basic library that we need to receive or send data manually, and to decode or encode our customized network protocol. It is not convenient actually. So from RC2, we have been refactoring networking with gRPC. The benefit of gRPC is very obvious. We don’t need to care how to handle network anymore, only focusing on our logic, and the code looks simple and clear. Meanwhile, users can build their own TiKV client with other programming languages easily. We have already been developing a TiKV client with Java.
For asynchronous framework. After receiving the request, TiKV dispatches the request to different threads to handle it asynchronously. At first, we used the MIO plus callback to handle the asynchronous request, but callback may break the code logic, and it is hard to read and write correctly, so now we have been refactoring with tokio-core and futures, and we think this style is more modern for Rust in the future. Sometimes, we also use the thread pool to dispatch simple tasks, and we will use futures-cpupool later.
For storage, we use rust-rocksdb to access RocksDB.
For monitoring, we wrote a rust client for Prometheus, and this client is recommended in the official wiki. For profiling, we use the jemallocator with enabling profile feature and use clippy to check our codes.
TODO…
Ok, that’s what we have done and are doing. Here are what we will do in the future:
- Make TiKV faster, like removing Box. we have used many boxes in TiKV to write code easily, this is not efficient. In our benchmark, dynamic dispatch is at least three times slower than static dispatch, so later we will use Trait Trait directly.
- Make TiKV more stable, like introducing Rust sanitizer.
- Contribute more Rust open source modules, like raft library, open-tracing, etc.
- Participate in other Rust projects more deeply, like rust-gRPC
- Write more articles about Rust on Chinese social media and organize more Rust meetups.
- Be a strong advocate of Rust in China.

Experience modern data infrastructure firsthand.



TiDB Cloud Dedicated
A fully-managed cloud DBaaS for predictable workloads
TiDB Cloud Starter
A fully-managed cloud DBaaS for auto-scaling workloads