
As GraphRAG is regarded as a better solution to the traditional RAG, TiDB Serverless – a MySQL compatible database but with built-in vector search – is also experimenting GraphRAG with our own database. So recently we wrote a tutorials to teach people who are interested in building GraphRAG how to build a Knowledge Graph based RAG step by step, and we place the whole code to Google Colab:
Try it in Google Colab: GraphRAG Step by Step Tutorials.
In this blog, we will only explain some key section of this tutorial.
Dependencies
In that tutorial, to start, we need to install the necessary Python libraries:
!pip install PyMySQL SQLAlchemy tidb-vector pydantic pydantic_core dspy-ai langchain-community wikipedia pyvis openaiIn that tutorial, we will walk through how to create a Knowledge Graph from raw Wikipedia data and use it to generate answers to user queries. This method leverages the DSPy and OpenAI libraries to process and understand natural language. So the above Python packages should be installed
Prerequisites
Before diving into code, ensure that you have a basic understanding of Python, SQL databases, and natural language processing principles. Additionally, you will need access to OpenAI’s API and a TiDB serverless instance for storing the graph.
Here is how to create a free TiDB Serverless cluster with built-in Vector Storage in it:
- Join the waitlist and sign up an account: https://tidb.cloud/ai
- Then create a cluster: Guide
Core Code
Part 1: Indexing
1.Set Up DSPy and OpenAI
Configure the DSPy settings to use OpenAI’s GPT-4 model. We choose to use GPT-4o as the language model.
from google.colab import userdata
open_ai_client = dspy.OpenAI(model="gpt-4o", api_key=userdata.get('OPENAI_API_KEY'), max_tokens=4096)
dspy.settings.configure(lm=open_ai_client)2.Load Raw Wikipedia Page
There is no need to write the loader ourselves, so in order to load Wikipedia, we choose LangChain’s WikipediaLoader directly. It can help us to load any Wikipedia page with format https://en.wikipedia.org/wiki/<item>
For this example, let’s use “Elon Musk”‘s Wikipedia page:
from langchain_community.document_loaders import WikipediaLoader
wiki = WikipediaLoader(query="Elon Musk").load()In fact, it loads https://en.wikipedia.org/wiki/Elon_Musk to memory.
3.Extract Raw Wikipedia Page to Knowledge Graph
Use the loaded Wikipedia content to extract entities and relationships:
pred = extractor(text = wiki[0].page_content)Look at the demo row in database(exclude description_vector column as it has 1536 length of float):
mysql> select id, name, description from entities limit 1 \G
*************************** 1. row ***************************
id: 1
name: Elon Reeve Musk
description: A businessman and investor, founder, chairman, CEO, and CTO of SpaceX; angel investor, CEO, product architect, and former chairman of Tesla, Inc.; owner, executive chairman, and CTO of X Corp.; founder of The Boring Company and xAI; co-founder of Neuralink and OpenAI; and president of the Musk Foundation.
1 row in set (0.16 sec)
mysql>4.Visualize the Graph
Show the graph using PyVis:
HTML(filename=jupyter_interactive_graph(pred.knowledge))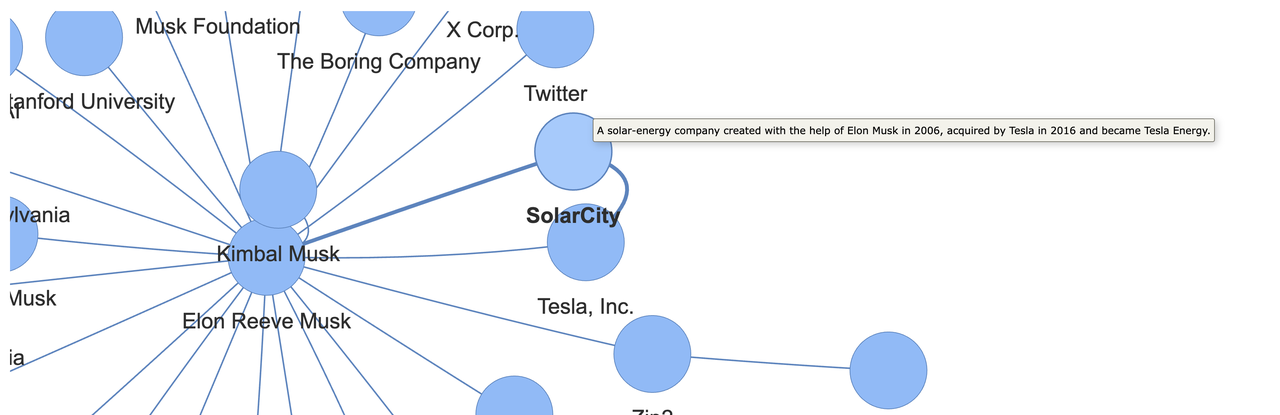
Note: we can see the relationship is different from the same concept in Graph database, in Graph databases, relationships between entities are typically represented with simple and concise labels, such as “have” or “belongs_to.” However, when defining relationships in TiDB Serverless, the representation is more complex and expansive. For example:
mysql> select * from relationships limit 1 \G
*************************** 1. row ***************************
id: 1
source_entity_id: 1
target_entity_id: 2
relationship_desc: Elon Musk is the founder, chairman, CEO, and CTO of SpaceX.
1 row in set (0.17 sec)
mysql>5.Save Graph to TiDB Serverless
Persist the extracted knowledge graph to a TiDB serverless database:
save_knowledge_graph(pred.knowledge)Done!
Part 2: Retrieve
6.Ask a Question
Define a query, such as finding details about Elon Musk:
question = "Who is Elon Musk?"7.Find Entities and Relationships
Retrieve entities and relationships related to the query from the database:
question_embedding = get_query_embedding(question)
entities, relationships = retrieve_entities_relationships(question_embedding)Still using SQL skills to search entity and relationship.
Part 3: Generate Answer
8.Generate an Answer
Using the entities and relationships retrieved, generate a comprehensive answer:
result = generate_result(question, entities, relationships)
print(result)Result:
Elon Reeve Musk is a prominent businessman and investor known for founding and leading several high-profile technology and space exploration companies. He is the founder, chairman, CEO, and CTO of SpaceX; the angel investor, CEO, product architect, and former chairman of Tesla, Inc.; the owner, executive chairman, and CTO of X Corp., which Twitter was rebranded into after its acquisition; the founder of The Boring Company and xAI; and the co-founder of Neuralink and OpenAI. He also serves as the president of the Musk Foundation...........Conclusion
This tutorial demonstrates a straightforward method to create a Knowledge Graph from Wikipedia data and utilize it to answer user queries using advanced natural language processing tools. The integration of DSPy with OpenAI and TiDB enables efficient processing and retrieval of information, making it a powerful tool for building intelligent applications.
Feel free to adapt the code to different Wikipedia pages or queries to explore the capabilities of this approach further.