

Business growth is an exciting milestone, bringing more users, transactions, and opportunities to innovate. However, with growth comes significant technical challenges, such as:
- Data Volume Explosion: Rapid user activity generates terabytes (TBs) to petabytes (PBs) of data that must be stored and managed efficiently.
- Increased Complexity: Applications must scale to support more users, while new features improve experiences and meet evolving demands.
- Operational Burdens: Traditional database solutions struggle to handle massive data growth, leading to downtime, delays, and costly operational overhead.
In this blog, we’ll explore how TiDB, an open-source distributed SQL database, addresses these business growth challenges. We’ll also walk through real-world examples from companies such as Bolt and Flipkart.
Bolt: A Fast Growing Mobility Company
As an example, Bolt is a fast growing mobility company in Europe, with more than 100 million users across more than 500 cities. The company has gained 400% growth since the pandemic. Bolt has also used MySQL as its backend database for many years. Here are some of the technical challenges it experienced while growing (see Bolt’s HTAP Summit 2023 session for more details):
- Manage hundreds of TBs to 1 PB in data volume.
- Deploy more than 100 services every day
- Make more than 100 database changes every week
- Generate 5~10 TBs of new data every month
- Hit single MySQL instance size limitation. The largest MySQL instance has 8TB data. Backup and restore for such a large MySQL instance took many hours, which is not acceptable for applications.
- Schema changes took up to two weeks with gh-ost/pt-online-schema-change for MySQL. This freezes the database for seconds when doing drop tables.
- MySQL’s master switch causes downtime when upgrading. This leads to bad connection handling for a spike in QPS, which impacts application availability.
Traditional Solution for Rapid Business Growth: Database Sharding

Facing a data growth challenge, the most traditional solution is to shard the backend database. Using this solution, in order to handle more connected users, more application servers would be deployed. And for the backend database, there will be multiple database instances. Additionally, a large table sharded into multiple sub-tables will be distributed across these multiple database instances.
But there are many drawbacks with database sharding including:
- Need to re-write the application’s code. Some database proxies try to hide sharding complexity from the application layer. But these proxies face operational complexities like resharding, inconsistency between sub-tables when doing schema changes, lack of cross-shard JOIN support, and inconsistency of cross-shard queries.
- Compromise on some SQL functionality like JOINs. Performing JOIN queries takes time as data gets partitioned into multiple shards across multiple database instances.
- As the data volume grows, splitting shards and resharding data is a headache.
- Keeping schema consistency between different shards is difficult.
- Disaster recovery is a complex job, while backup to a consistent database snapshot needs extra effort.
Why We Need a Scalable Distributed SQL Database for Rapid Business Growth
To face rapid business and data growth head on, a scalable distributed SQL database with the following capabilities can get the job done:
- Horizontal scalability: An ability to add more nodes to the database to satisfy data and QPS growth.
- Low operational complexity: With a scalable distributed SQL database, there’s no need to change the application layer’s code, compromise on SQL syntax like JOINs, or perform out-of-the-box schema changes, backups, change data capture (CDC), and data loading.
- Low read/write tail latency with high data volumes: A scalable distributed SQL database has p99 single-digit millisecond latency, even with hundreds of TB data.
- High availability: A scalable distributed SQL database has greater than 99.99 availability, and can tolerate AZ level failure
For the past decade, we have been focusing on building just such a scalable distributed SQL Database.
TiDB: A Scalable, Open Source Distributed SQL Database for Rapid Business Growth
TiDB is an open-source, cloud-native, distributed SQL database for elastic scale that also happens to be MySQL compatible. One can think of TiDB as a limitlessly scalable MySQL database but with added strengths such as distributed data aggregation and data analytics. Applications connect to TiDB’s compute layer using the MySQL protocol; workload and data automatically balances across different nodes.
Unlike MySQL or PostgreSQL, TiDB functions as a cloud-native distributed system on Day 1. This choice makes TiDB’s up boundary higher in terms of scalability. As shown in the below diagram, TiDB has a disaggregated compute and storage architecture. This allows the compute and storage layers to scale independently for better efficicency.

TiDB Can Scale to 1 Million QPS
Flipkart is the largest eCommerce company in India. With over 400 applications, thousands of microservices, and countless varieties of end-to-end ecommerce operations running across over 700 MySQL clusters, Flipkart runs one of India’s largest MySQL fleets.
In order to satisfy large request throughputs from its annual Big Billion Days (BBD) activities, Flipkart needed a scalable SQL database. This database had to handle such high throughput with low latency while consolidating multiple MySQL instances into one SQL database to reduce operational costs. In 2020, Flipkart discovered TiDB, and TiDB was first deployed in early 2021.
Flipkart performed a 1 million QPS test on TiDB to verify the database’s scalability. As a result, the company achieved 1 million QPS with single-digit millisecond tail latency across 32 TiDB nodes. Meanwhile, because of TiDB’s high compression data storage, Flipkart’s data footprint decreased by 82% compared to MySQL.

TiDB Can Add an Index for a 40 TB Table in One Hour
As we touched on earlier with Bolt, changing table schemas to fit the evolution of applications is very common. The company needed to make more than 100 schema changes each week. That means adding an index was one of the company’s most frequently used schema changes. As a large scale SQL database, TiDB supports online schema changes out of the box, which means schema changes will not block foreground requests. Meanwhile, adding an index in TiDB is very fast.
The below diagram shows how TiDB can add an index quickly through its Distributed eXecution Framework. In this framework, each TiDB node is responsible for a part of the job, scans corresponding data ranges, generates SST files, and then ingests those files into TiDB’s storage layer. Meanwhile, the new write (i.e., insert/update/delete) of this table will be tracked and recorded.

Multiple Adding Index Testing
We performed multiple adding index tests for a 40 TB table. The below table shows that when we ran the add index in single node mode, it took around 14h to finish the whole job. However, when we ran it in distributed mode, it took only 1h to scale horizontally, because there are 14 TiDB nodes in this cluster. Next, when we ran a single statement to add four indices for this 40 TB table, it only took 1h 27m because these four indices reused the same scan result during the procedure.
| 40 TB | Nodes | CPU | Memory |
| TiDB | 14 | 15 cores | 28 GB |
| TiKV | 20 | 8 cores | 28 GB |
| PD | 3 | 2 cores | 5 GB |
| TiDB DXF (Distributed eXecution Framework) | ALTER TABLE item ADD INDEX idx(`product_id`); | 59m 46s |
| TiDB DXF | ALTER TABLE item ADD INDEX idx_pid(`product_id`), ADD INDEX idx_mid(`merchant_id`), ADD INDEX idx_ct(`created_time`), ADD INDEX idx_miid_misid(`merchant_item_id`, `merchant_item_set_id`); | 1h 27m 09s |
| TiDB DXF | ALTER TABLE item ADD UNIQUE INDEX idx(merchant_id, item_primary_key); | 1h 6m 9.11s |
| TiDB Local (single-node mode) | ALTER TABLE item ADD INDEX idx(`product_id`); | 14h 38m 09s |
TiDB Can Backup a 300 TB Cluster in One Hour
Backup is a must-have requirement to ensure data can be recovered after a severe disaster. By default, TiDB replicates data across multiple nodes to achieve high data durability and availability as the data backend of applications.
TiDB also supports two kinds of backups: Snapshot full backup and incremental change log backup. The full snapshot backup dumps a consistency snapshot of the whole cluster, a specified database, or table. From there, it uploads the backup to remote storage (such as Amazon S3). Each TiDB storage node uploads their data in the form of parallel SST files.
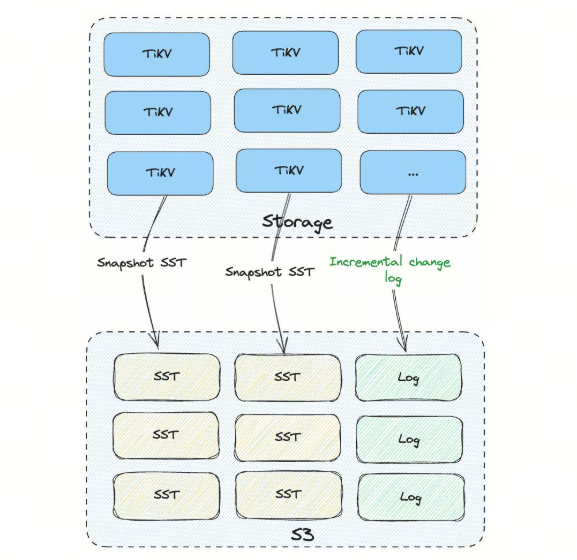
We performed two sets of tests for two different TiDB clusters containing 100 TB and 309 TB. The first 100 TB backup took 45 minutes, and the 309 TB backup took 1h 4m. While the 309 TB cluster has 3x the data size compared to the first cluster, the total backup time took only a little longer than the first cluster. This is due to the amount of data contained in each storage node. For the 309 TB cluster, each storage node contains 3.1 TB, which is slightly larger than the first cluster.
| Cluster Size | 100 TB | 309 TB |
| Storage Nodes | 42 | 100 |
| Data Volume Per Node | 2.6 TB | 3.1 TB |
| Total Time | 45m | 1h 4m |
Conclusion
As businesses grow, managing massive data volumes and scaling applications become critical challenges. Traditional solutions like database sharding introduce complexity, operational overhead, and functional limitations. But as we’ve discussed, TiDB provides a modern, scalable, and resilient distributed SQL database that eliminates these challenges.
With proven success in handling petabyte-scale data, millions of transactions per second, and complex operational demands, TiDB enables businesses to scale efficiently while maintaining high availability and performance. For companies navigating rapid growth, TiDB offers a future-proof solution to handle scaling, high-volume data, and evolving business needs.
Want to dive deeper into TiDB? Check out our free on-demand webinar, Introduction to TiDB, and learn more about key use cases across a variety of industries including Financial Services, eCommerce, Gaming, and SaaS.
Experience modern data infrastructure firsthand.



TiDB Cloud Dedicated
A fully-managed cloud DBaaS for predictable workloads
TiDB Cloud Serverless
A fully-managed cloud DBaaS for auto-scaling workloads