
Elevate modern apps with TiDB.
Author: Yong Duan, DBA at Mashang Consumer Finance
The choice of database can significantly impact operational efficiency, especially in high-concurrency, cross-center hot backup scenarios. This blog delves into the experiences and challenges faced by Mashang Consumer Finance during their selection and use of TiDB, compared to MySQL. We’ll explore practical applications, highlighting the strengths and weaknesses of each database.
Mashang Consumer Finance Co., Ltd. (or “Mashang Consumer”) is a trailblazer in the financial technology space, backed by a consumer finance license from the former China Banking and Insurance Regulatory Commission. Since its inception in June 2015, Mashang Consumer has rapidly expanded, securing three rounds of capital increase and pushing its registered capital beyond 4 billion yuan. With a staggering cumulative transaction volume surpassing one trillion yuan, the company’s growing data demands have introduced new and complex challenges for its database infrastructure.
MySQL is a well-established relational database that has become one of the most widely used in the industry. Over the years, it has proven itself by offering essential features like data security, transaction processing, high availability, and performance optimization. Its stability and reliability have made it a popular choice, particularly in small to medium-sized enterprises and traditional financial industries.
For financial institutions, data security is paramount. MySQL’s reputation for high reliability and stability is a key reason it’s favored by the financial sector, especially for managing large volumes of transaction records, account management, and risk management. Other critical factors include scalability, performance, cost-effectiveness, and security compliance.
Scalability is particularly vital in finance, where MySQL supports high-availability architectures like master-slave replication, read-write separation, and cluster deployment. These features allow MySQL to handle the increasing data processing demands and concurrent access typical in the financial industry. However, while MySQL can achieve read scalability by adding slave nodes, write scalability is more challenging and requires sharding—a process that can be complex to implement.
MySQL has several limitations, particularly in the following areas:
These issues can be summarized as MySQL’s inability to overcome the single-machine performance bottleneck. Additionally, high availability and disaster recovery present challenges:
Based on these pain points, our experience with MySQL typically progresses through three stages:
Each of these solutions has its own set of shortcomings, which will be explored in detail below.
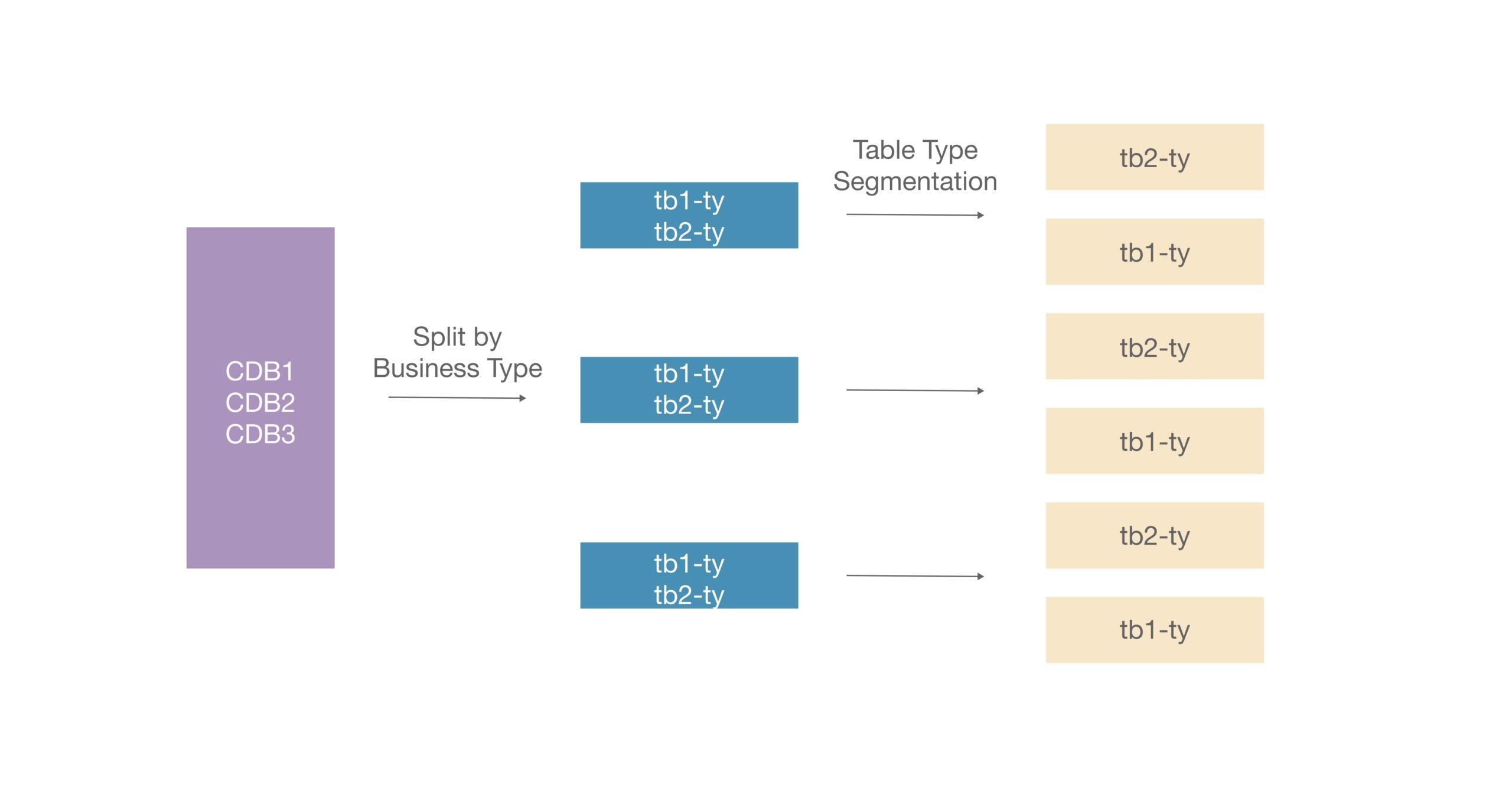
In the early stages of a business, it’s common to integrate multiple databases within a single cluster. However, as the business grows and the workload increases, this approach often becomes unsustainable. To manage the rising pressure, databases are split, with each business type assigned to a separate cluster to balance the load. If splitting the database isn’t feasible, tables are divided based on specific business scenarios. For instance, if business A uses three tables and business B also uses three tables, the tables for business A might be placed in one cluster while those for business B are placed in another.
Despite these efforts, this solution has significant limitations. The primary issue is the concurrency of a single database. Even after splitting, once the table data reaches a certain size, it still may not meet the business’s concurrency demands. Furthermore, some business models require hundreds of tables to be joined during routine operations, making it impractical to split them. Another challenge arises with cross-database associations—when tables from different databases need to be joined, splitting makes this impossible to achieve.
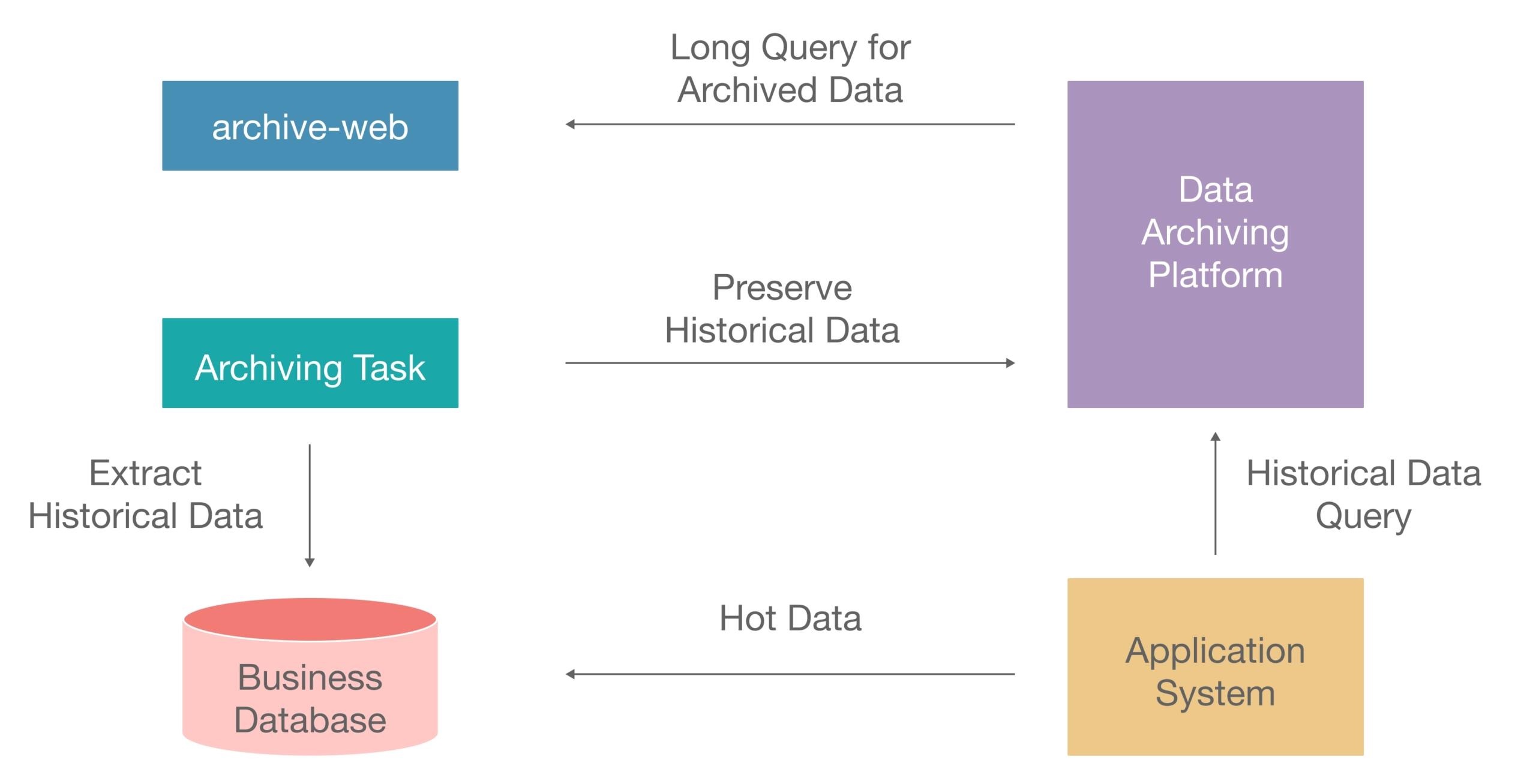
When the data volume of a single database has reached a certain scale and can no longer be split, historical data archiving is necessary. For example, data from three months ago may not be used frequently, so it can be directly moved to an archiving platform. The above diagram illustrates a typical data archiving process: first, provide an archiving platform, with hot data stored in the online database cluster and historical data stored in the archiving platform.
However, this solution also has some limitations. For example, if historical data is retained for three years and all three years’ worth of data is frequently accessed and the data volume is very large, it is impossible to separate hot and cold data, making archiving infeasible in this scenario. Mashang’s archiving platform is often built on the HBase big data platform, which cannot meet high-frequency query requirements. Additionally, if it is a single cluster and the hot data from the past three months has already exceeded the single-machine performance bottleneck, this solution is also inapplicable.
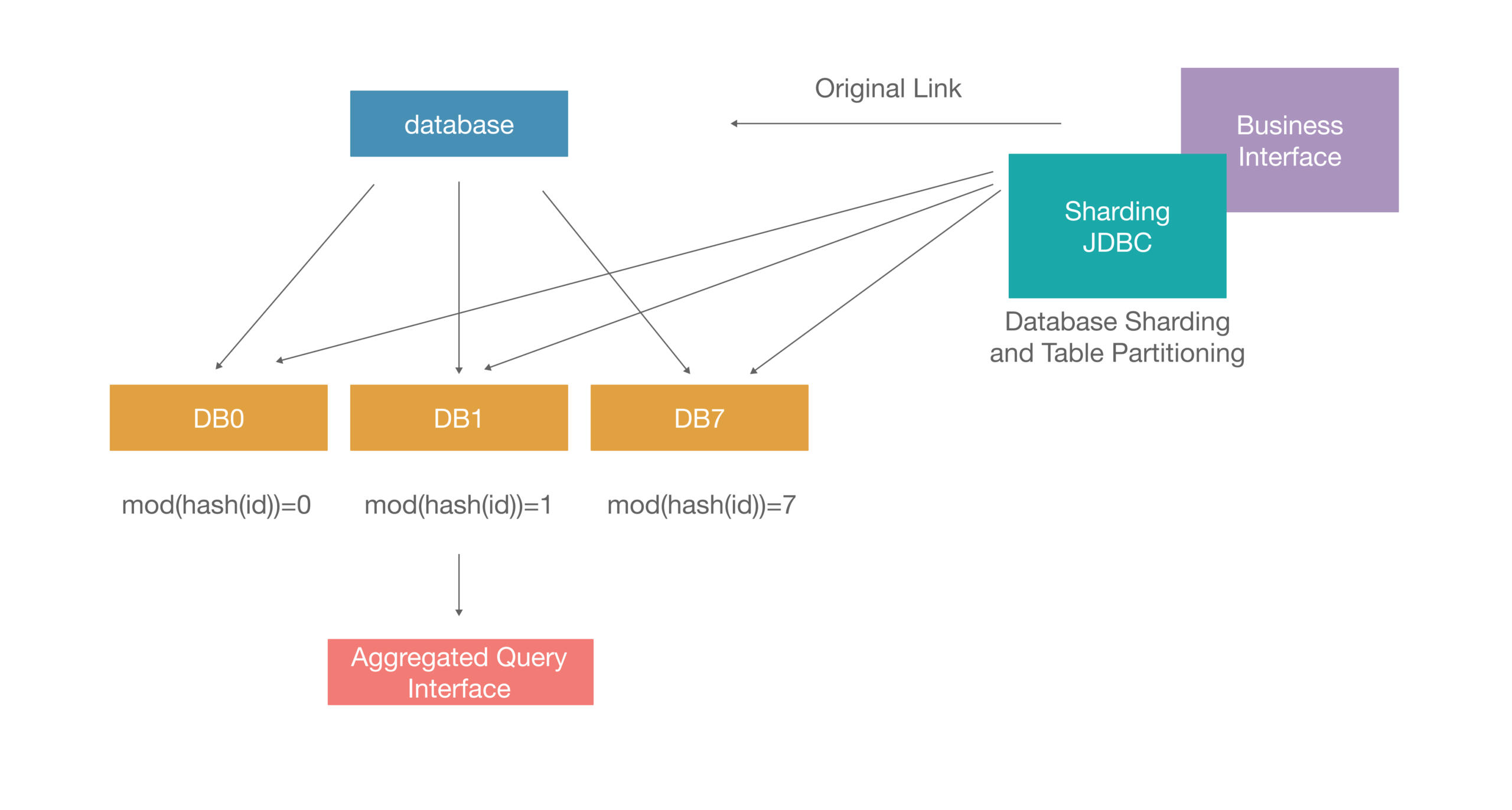
At the MySQL level, the ultimate solution is what is commonly referred to as database and table sharding. The basic logic is to split a single database into multiple databases by hashing the database’s ID, then dividing it into several databases. This solution also has some challenges.
First, aggregate queries: how do you handle related queries across so many databases? Second, when adding shards, the difficulty of business modification is significant, which also increases maintenance costs.
For example, if there are 64 shards and you need to add a field, without an automated management platform, you would have to manually add this field one by one. Additionally, the difficulty of business modification is substantial when splitting a single database into multiple databases. Each time you split a database, you face the challenge of modifying the business operations accordingly.

Based on the above issues, Mashang were eager to introduce a distributed database. At that time, their database selection focused on the following aspects:
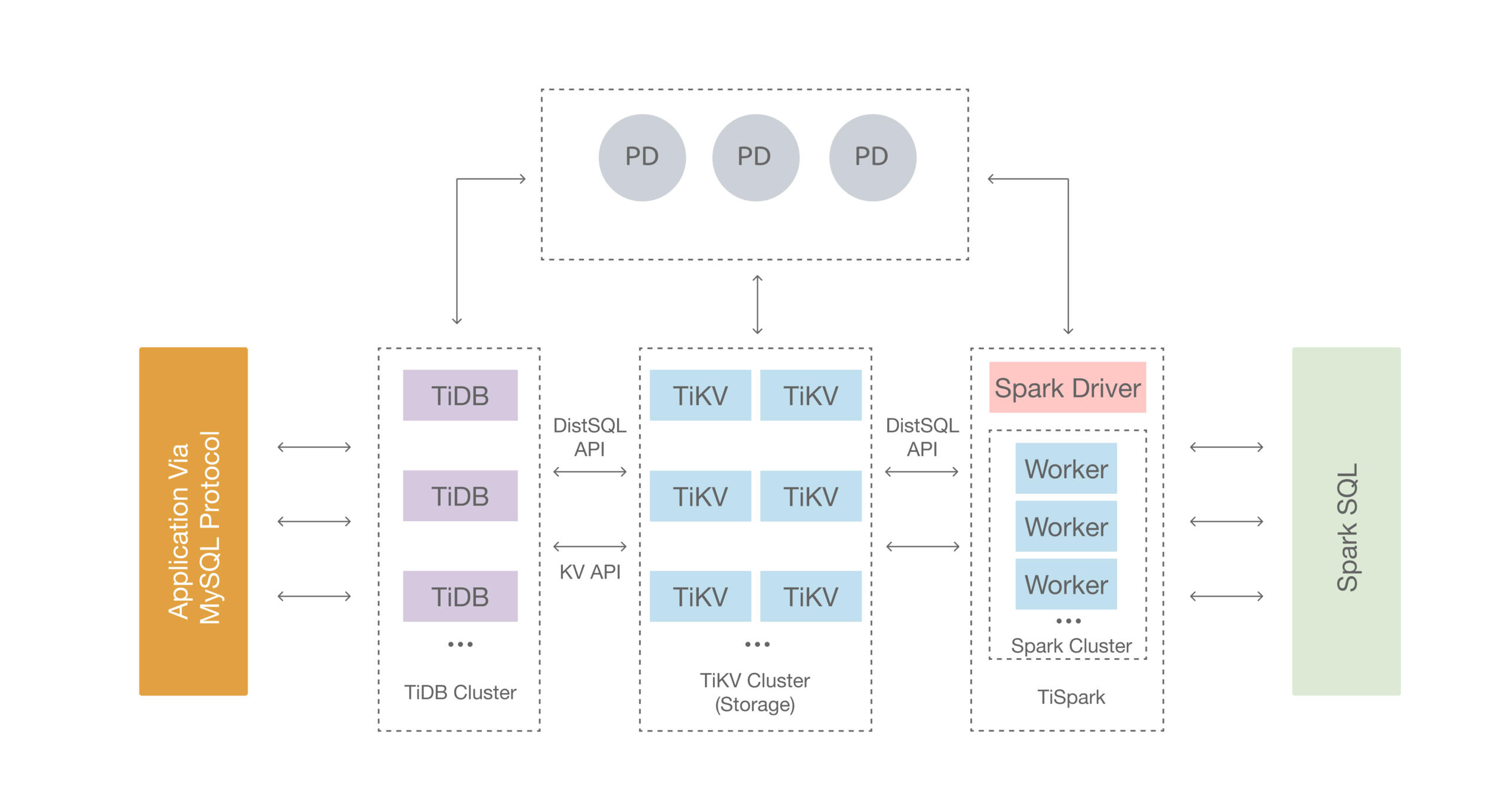
Based on the above mentioned selection criteria, here are the key architectural features of TiDB:
Based on these characteristics of TiDB, we made a key feature comparison between TiDB and MySQL-MGR.
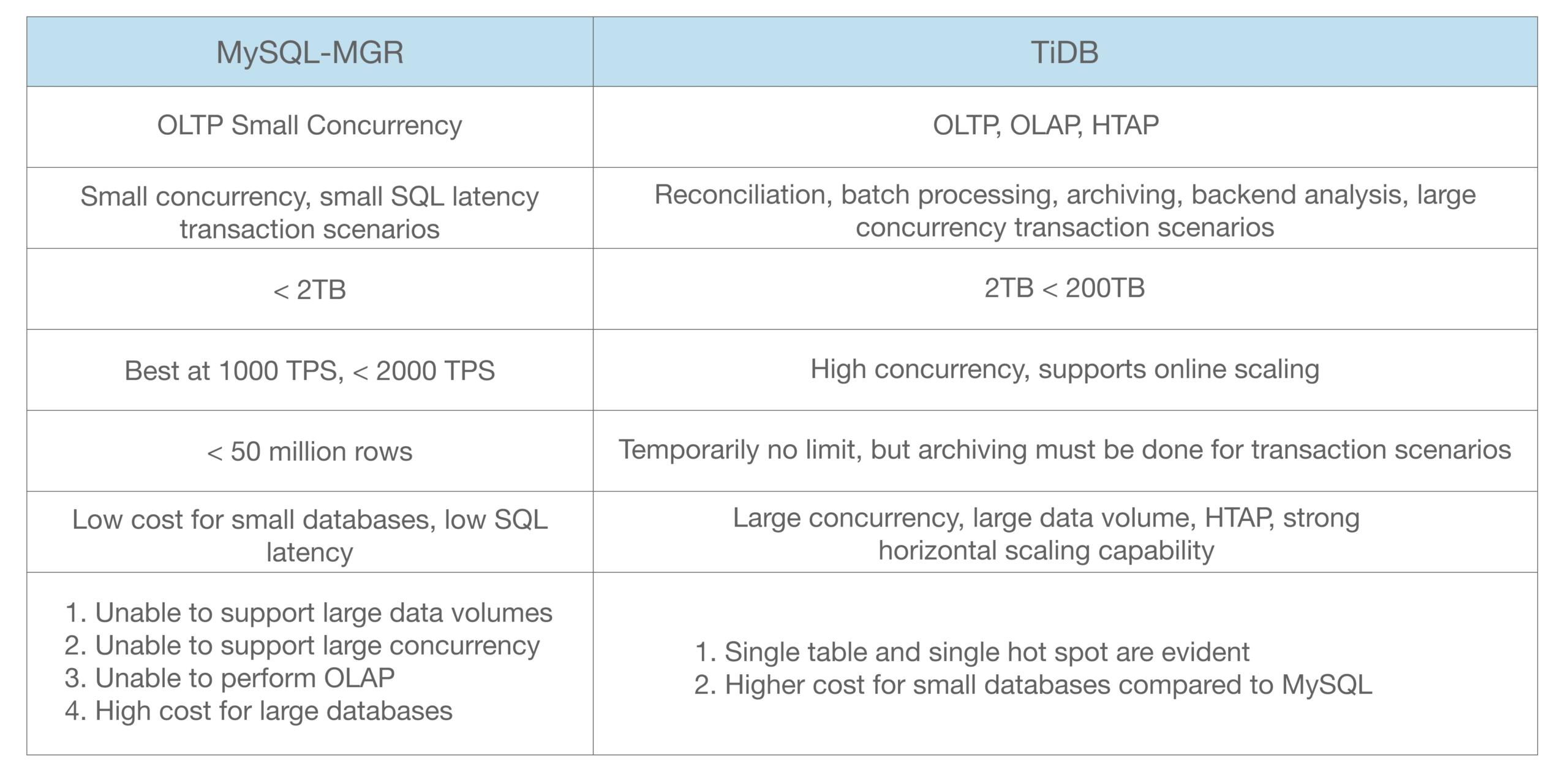
For MySQL, Mashang has a complete SOP (Standard Operating Procedure). For instance, development standards are strictly defined, and data volume must be within a certain range to use MySQL. If it exceeds this range, sharding is necessary. Additionally, strict guidelines have been established for parameters that must be met, such as limiting the number of tables involved in join queries, all of which are based on the limitations of MySQL.
Supported Scenario Types: MySQL supports small concurrency OLTP scenarios, while TiDB can support both OLTP and OLAP. If the scenario involves small SQL concurrency and low latency transaction systems, MySQL’s performance is actually better than TiDB. However, for reconciliation, batch processing, summary analysis, and high concurrency transaction scenarios, TiDB has significant advantages.
Data Volume Requirements: In their production environment, they use MySQL for data volumes below 2TB and TiDB for data volumes between 2TB and 200TB. Currently, their transaction system data volume requirement is within 50TB; for volumes exceeding 50TB, the business must be archived. In terms of TPS (Transactions Per Second), MySQL performs relatively well with TPS below 2,000. If business growth is particularly rapid and online expansion is necessary, it is relatively difficult for MySQL, while TiDB can support online horizontal scaling.
Single Table Size: For single table limitations, they generally require MySQL tables to be within 50 million rows, whereas TiDB does not impose many restrictions on single table size.
Overall, MySQL has clear advantages in single-machine performance and maturity. But TiDB demonstrates excellent scalability and strong consistency guarantees in handling distributed, high concurrency, and large-scale data scenarios.
Massive Transaction Data Storage and Retrieval
Business Characteristics
Difficulty in Implementing with MySQL
Server Specifications:
The information above represents a typical online business system message platform of Mashang Consumer Finance, which is also one of their 13 core systems. The current total data volume, with three replicas, has reached 39 TB, with the largest table containing over tens of billions of rows, and a monthly increase of approximately 1.9 TB.The main characteristics of the message platform business are:
Using MySQL for this business would be particularly challenging, requiring timely database and table sharding, with the estimated cost being about 2-3 times that of TiDB. After introducing TiDB, we used 36 TiKV nodes, each server configured with 40 cores, 128GB RAM, and 2TB storage, keeping latency within 500 milliseconds. Although the QPS (Queries Per Second) may not seem high, the actual tables contain tens of billions of rows, making this QPS quite significant. Any fluctuation would at least double or triple the latency.
Mashang’s practical application of TiDB is mainly divided into the following four scenarios:
Data Warehouse and Analytics Platform
Key Features of the Solution:
The second scenario is the data warehouse and analytics platform. Their database is sharded, with online data divided into 64 shards. Data is aggregated into TiDB through DM (Data Migration) for analysis and querying. The key feature of this solution is that TiDB allows for easy horizontal scaling. No matter how much their business data grows, they can add more machines once synchronized via DM. Using DM for merging is relatively straightforward, eliminating the need for complex join queries through an HBase archiving platform and avoiding the need to design complex architectures for synchronization solutions.
Multi-Center Deployment
The above diagram shows their current multi-center deployment architecture. Data Center A acts as the primary data center, deploying 3 TiDB instances, with each TiKV shard deployed across 3 data centers. The third data center serves as the voting data center for the majority but also stores real data. The second data center serves as a hot standby. Each data center has the same number of TiDB and TiKV instances. TiDB meets the standards for one-write-multiple-read, dual-active, multi-active, RTO, and RPO very well.
Implementing multi-center deployment with MySQL is relatively tricky because master-slave delay is unavoidable. To reduce master-slave delay, sharding is required, which is very challenging to achieve. For this architecture, choosing TiDB makes deployment much more straightforward, but there are still a few challenges:
In summary, MySQL has clear advantages in single-machine performance and maturity, which is undeniable given its usage across various industries and years of development. On the other hand, TiDB demonstrates excellent scalability and strong consistency guarantees in handling distributed, high-concurrency, and large-scale data scenarios. TiDB’s Raft protocol and multi-replica principles ensure good consistency. The choice between the two should be based on project requirements, data scale, team skills, and other factors. Due to the unique nature of the financial industry, the choice of database must also meet regulatory requirements, stability, performance, security, and technical support.
When it comes to selecting a database, there is no one-size-fits-all solution. The best database is the one that fits your business needs.

Elevate modern apps with TiDB.