
Real-Time Analytics with TiDB: How to Handle Petabytes of Data Efficiently
Introduction to Real-Time Analytics
In today’s data-driven world, real-time analytics has emerged as a pivotal element for businesses aiming to make swift, data-informed decisions. Real-time analytics refers to the instantaneous processing and analysis of data as it gets generated, thus enabling organizations to respond to events almost as quickly as they happen. This capability is critical in various domains, from financial trading and fraud detection to dynamic pricing and personalized customer experiences.
However, handling petabytes of data in real-time introduces several challenges:
- Volume and Velocity: Handling vast volumes of data arriving at high velocity requires a robust infrastructure that can scale horizontally.
- Low Latency: Real-time analytics necessitates minimal lag between data ingestion and insights generation, which demands optimized systems for low-latency data processing.
- Consistency and Availability: Ensuring data consistency while maintaining high availability is crucial, especially in distributed environments where network partitions can occur.
- Complex Query Processing: Real-time analytics often involves complex queries that need to be executed efficiently on large datasets.
Distributed databases play an essential role in overcoming these challenges. They offer the scalability and robustness required to process enormous datasets distributed across multiple nodes, providing a foundation for real-time analytics applications.
TiDB Architecture for Massive Data Handling
TiDB is an open-source, distributed SQL database that excels in handling hybrid transactional and analytical processing (HTAP) workloads. Its architecture is meticulously designed to tackle the challenges associated with real-time analytics on petabyte-scale data.
Overview of TiDB’s HTAP Capabilities
TiDB combines the strengths of both OLTP (Online Transactional Processing) and OLAP (Online Analytical Processing) systems, thanks to its unique HTAP capabilities. It supports real-time transactions and analytics within a unified platform, eliminating the need for separate systems and reducing data latency.
Key Components
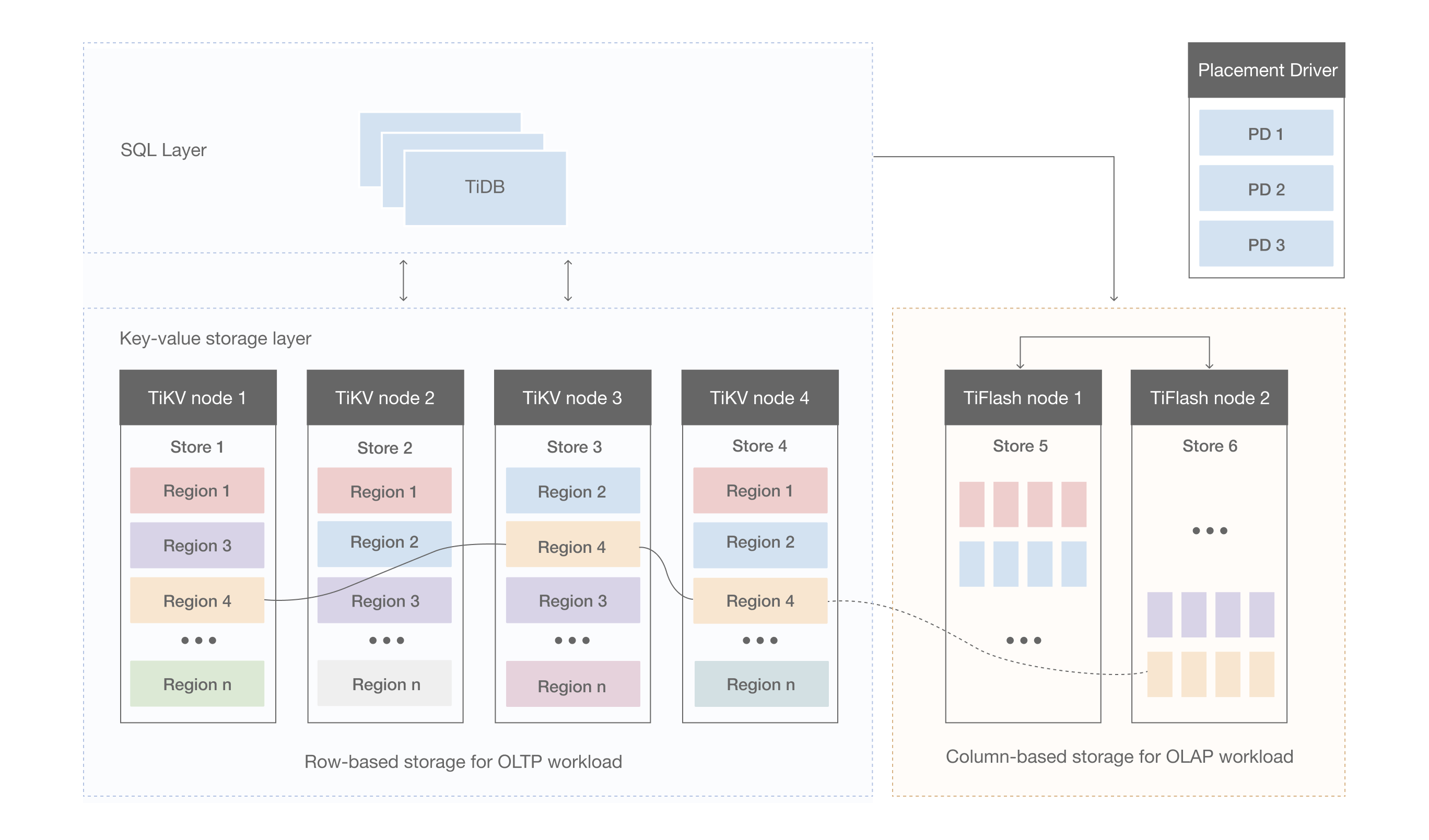
- SQL Layer:
- The SQL layer in TiDB manages the query processing and optimization. It translates high-level SQL queries into efficient execution plans, leveraging TiDB’s distributed architecture to execute those plans across multiple nodes.

- Placement Driver (PD):
- PD is the brain of the TiDB cluster, responsible for managing metadata, orchestrating data placement, and balancing the load across the cluster. It ensures data availability and consistency via the Raft consensus algorithm.
- TiKV Store:
- TiKV is the distributed storage engine that stores data as key-value pairs. It provides high availability and fault tolerance through the Raft consensus algorithm. TiKV supports horizontal scaling, allowing the system to handle increasing workloads seamlessly.

Scalability and Horizontal Scaling Techniques
TiDB’s architecture separates storage from computing, enabling independent scaling of resources based on workload requirements. This design ensures that users can add more storage or compute nodes dynamically without causing downtime or disrupting services.
Data Sharding and Partitioning
TiKV automatically shards data into small, manageable pieces called Regions. A Region is a range of keys, and TiKV splits Regions that grow too large, ensuring balanced data distribution across the cluster. This automatic sharding enhances performance by enabling parallel data processing and avoids single points of failure.
Optimizing Performance for Real-Time Analytics
Achieving optimal performance for real-time analytics involves several strategies, from efficient data ingestion to advanced indexing techniques.
Efficient Data Ingestion and ETL Processes
TiDB supports high-throughput data ingestion, allowing rapid ingestion and transformation of data:
- Batch Processing: Use batch processing techniques to ingest large volumes of data efficiently. TiDB’s architecture supports bulk operations, minimizing the overhead involved in individual inserts.
- Streaming Ingestion: Stream processing frameworks like Apache Flink can be integrated with TiDB to handle continuous data streams, ensuring that real-time data is available for analysis as soon as it arrives.
Real-Time Query Processing and Low-Latency Reads/Writes
Real-time analytics requires systems that can process queries with near-zero latency:
- Columnar Storage with TiFlash: TiFlash, a columnar storage engine in TiDB, is optimized for OLAP workloads. It maintains a real-time replica of TiKV’s row-based storage but stores data in a columnar format, significantly speeding up analytical queries.
- Optimized Query Execution: TiDB’s SQL engine uses sophisticated optimization techniques, including cost-based optimization, to generate efficient execution plans for complex queries.
Leveraging TiDB’s Built-In Caching Mechanisms
TiDB uses caching mechanisms to reduce query response times and improve performance:
- Cached Execution Plans: Frequently used query plans are cached, reducing the overhead of query optimization for repeated queries.
- Data Caching: TiDB caches hot data in memory, reducing the need to access disk storage for frequently accessed datasets.
Indexing and Query Optimization Strategies
Proper indexing and query optimization are crucial for achieving high performance:
- Secondary Indexes: Use secondary indexes to speed up query processing. TiDB supports global secondary indexes, which can significantly improve the performance of complex queries.
- Covering Indexes: Implement covering indexes to reduce the need to fetch additional columns from the table, thus speeding up query processing.
- Query Hints: Use query hints to influence the optimizer’s choice of execution plans. This can lead to more efficient query processing by choosing the optimal paths for data retrieval.
Case Studies and Practical Implementations
Real-world scenarios exemplify TiDB’s capabilities in handling massive datasets and enabling real-time analytics:
Success Stories of Companies Using TiDB for Real-Time Analytics
Numerous companies have leveraged TiDB for their real-time analytics needs, achieving substantial improvements in performance and scalability:
- Case Study 1: A financial services company implemented TiDB to handle high-frequency trading data. By leveraging TiDB’s HTAP capabilities, they integrated transactional and analytical processing, reducing data latency and improving decision-making speed.
- Case Study 2: An e-commerce giant uses TiDB to analyze customer behavior in real-time. By using TiFlash for analytical queries, they achieved faster insights and improved customer targeting strategies.
Architectural Diagrams and Workflows
Diagrams showcasing TiDB’s architecture and workflows help in understanding its application in real-world scenarios:
Lessons Learned and Best Practices
Implementing TiDB in a production environment yields several valuable lessons:
- Lesson 1: Monitor and optimize the performance periodically. Use tools like TiDB Dashboard to gain insights into cluster performance and identify bottlenecks.
- Lesson 2: Leverage horizontal scaling for growing workloads. Plan for potential data growth and scale the cluster dynamically to maintain performance levels.
- Lesson 3: Ensure proper indexing strategies. Regularly review and update indexes to match changing query patterns and dataset characteristics.
Conclusion
Real-time analytics necessitates robust, scalable, and low-latency data processing capabilities. TiDB, with its HTAP architecture and distributed design, stands out as an ideal solution for real-time analytics on petabyte-scale data. By following best practices in data ingestion, query optimization, and performance tuning, organizations can harness TiDB’s full potential to gain insightful, real-time analytics and drive informed decision-making.
For further details on TiDB and its capabilities, visit TiDB Best Practices and explore our comprehensive documentation.
By adopting these strategies and leveraging TiDB’s advanced features, organizations can efficiently handle massive data volumes and achieve real-time analytics, staying ahead in today’s data-centric world.