

Author: Max Liu (CEO at PingCAP)
Transcreator: Ran Huang; Editor: Tom Dewan
This article is based on a talk given by Max Liu at PingCAP Infra Meetup.
TiDB is an open source, distributed SQL database started by PingCAP. As the CEO of PingCAP, I’m also TiDB’s principal product manager, with veto power on the important features of our product. Rather than adding more features, my duty at PingCAP is to cut down unnecessary features so that TiDB stays focused yet flexible.
In this post, I will talk about the philosophy behind TiDB’s evolution, and, as a product manager, how I figured out where TiDB would be going and how we finally got there.
TiDB’s evolution philosophy
In the software industry, there’s a long-established strategy: “make it work, make it right, and make it fast.” We adhered to this strategy all along.
Make it work
Before we started to build TiDB, we did some simple user research. What problems were troubling current database users? What kind of database should we build? The research told us that users wanted a distributed database that scales out automatically to get rid of data sharding. To meet this user requirement, we began two years of development.
Build a SQL layer
During the two years, we made many choices about how TiDB would evolve. For example, TiDB must adopt a multi-layered architecture; otherwise, we couldn’t control its complexity.
TiDB has two layers: the SQL layer and the key-value (KV) layer. So which layer should we start with? It didn’t matter which one we chose, but we had to start somewhere. What criteria should we use to make the choice?
That’s when we determined TiDB Principle #1: Always stay close to our users. The closer we stay to our users, the quicker we can get their feedback and verify if our idea works. Apparently, the SQL layer is relevant to our users, since they don’t have to know about the KV layer. So we started there and built the SQL layer on top of an existing KV storage engine. Even today, most TiDB users aren’t aware of the KV layer. They write SQL, run the query, and get the result. Whether the bottom storage engine is changed or optimized is none of their concern.
In September 2015, we released TiDB to the open source community. It didn’t have a storage layer and ran on top of HBase. After the system worked as expected, we contacted the users we had surveyed earlier and asked for their feedback.
Provide KV storage
But no one would adopt the prototype. Because TiDB didn’t have a KV storage layer, users needed to install Hadoop, Zookeeper, the Hadoop Distributed File System (HDFS), and HBase to make it work. That would be a complete disaster, so potential users turned us down. We immediately started developing the distributed KV layer, which in turn brought about new choices and new considerations.
The first consideration was correctness. For critical industries, such as banking, insurance, and securities, data correctness is the most important factor of a database. No one would use a database that processes data incorrectly.
Secondly, the implementation should be simple. No user would tolerate a product that’s difficult to use. One of our early goals was to make TiDB easier to use than HBase, with a smaller code base. Even today, TiDB’s code base is less than one tenth the size of HBase’s.
Thirdly, we considered extensibility. TiDB’s architecture consists of multiple layers, such as the SQL layer and the KV layer. But the KV storage layer itself is also multi-layered. It supports the Raw KV API and transaction API and is quite extensible. Some users appreciated this design and made great use of our Raw KV API.
Next, high performance and low latency. Although a database can never be too fast, we didn’t put much focus on improving the performance. In fact, “make it fast” is the last step in our strategy. We believed there were other aspects that were more important in the early stage, such as the architecture, usability, and an active community. Without these aspects, a database system that simply provides high performance is not a mature, workable solution. It would be like making a car with only an engine and four wheels—it’s lightweight, fast, and a convertible, but no one dares to drive it on the road. That’s why we need to take a holistic approach in considering things. For the same reason, we chose to write the KV layer in Rust, not just because Rust performs best, but also for its safety and ability to handle extremely high concurrency.
Last but not least, stability. We put extra emphasis on each layer’s stability. For the bottom storage engine, we chose a very stable candidate, RocksDB, and built our KV storage, TiKV, on top of that.
Another three months went by, and we released TiKV. We got back to one potential user and asked them to consider TiDB again. However, they turned us down again because they were afraid that it might crash and lose their data.
Ensure data safety
To resolve the user’s concerns, we started developing a new component, TiDB Binlog. It replicates the TiDB binary log to MySQL in real time. If TiDB ever fails, the user can switch back to MySQL, and services continue as usual.
When our first user finally put TiDB online, the architecture was as follows:
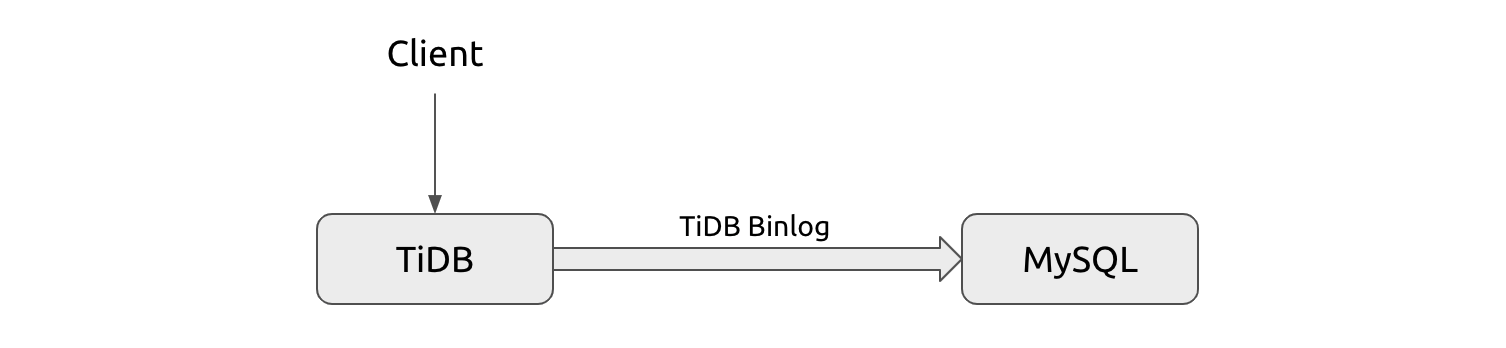
The first user’s architecture
The user application connected to TiDB via a client, and TiDB replicated data to MySQL via TiDB Binlog. The system worked as expected. After a while, however, the user took down the backup MySQL cluster because:
- MySQL could no longer handle the massive amount of binary logs.
- TiDB was stable and highly available, which boosted user confidence.
So, though the process was full of twists and turns, we finally proved that our concept worked.
Make it right
When it comes to data, correctness is everything. It’s not enough to have an interesting theory or good design. You need a real product that delivers correct results day after day.
TLA+ verification
The distributed database industry has its own methodology: verify the algorithm and then implement it. To make sure that the whole system is theoretically feasible, we used TLA+ to verify all the core algorithms and open sourced the verification.
Tens of millions of test cases
The transition from theory to practice is not an easy step to take. We must test the system with massive test cases. In normal software, the number of test cases seldom exceeds 100,000. In TiDB, our test cases reached tens of millions.
Of course, we can’t write all those cases by hand. Because TiDB is compatible with the MySQL protocol, we could use some of their test cases. These test cases include applications, framework, and management tools. Because many apps (such as WordPress and numerous object-relational mapping (ORM) tools depend on MySQL, we could run them on TiDB and know whether TiDB’s compatibility with MySQL worked as expected. We also tested TiDB with many MySQL management tools, such as Navicat and PHP admin.
We also used TiDB as the backend of our internal Confluence and Jira tools. Though the dataset was not large, we wanted to have as many tests as possible in different applications. This is also eating our own dog food.
Fault injection 24/7
Around-the-clock fault injection testing consumed a lot of our energy. As the system scaled up, we invested more and more in this testing. Now, we have hundreds of servers running fault injection tests at the same time.
Moreover, to better test our system, we started a Chaos Engineering project, Chaos Mesh, to inject various faults into distributed systems. We open-sourced Chaos Mesh and donated it to the Cloud Native Computing Foundation (CNCF).
Make it fast
As we strove to make TiDB work and then make it right, more and more users showed up. Our focus also gradually shifted to making TiDB fast.
Make OLAP available
Among our users, some treated TiDB as a transaction-supported, real-time data warehouse. One of them told us, “We replaced Hadoop with TiDB, with 10+ TB data.”
We were surprised. We didn’t design TiDB to be an analytical database, nor a data warehouse. We were just trying to build a distributed Online Transactional Processing (OLTP) database. But the user is always right. TiDB was compatible with MySQL—users could easily hire MySQL DBAs to manage TiDB—and, more importantly, it was faster than Hadoop. So why not simply use TiDB?
Therefore, surprised as we were, we caught a glimpse of a potential value of TiDB we hadn’t realized—an Online Analytical Processing (OLAP) database. So we asked our users what other pain points they had. Some mentioned the support for Apache Spark.
After that, we developed TiSpark, a computational layer for answering Spark queries on top of TiDB. With TiSpark, TiDB became a well-functioning database for both OLTP and OLAP workloads.
Make OLTP fast
Just before we were about to further optimize the OLAP capabilities, a large number of OLTP users reported loads of problems, including incorrect execution plans, uneven hotspots, Raft store single thread bottlenecks, and slow report generation. So we paused the OLAP development for a while and addressed users’ most urgent problems. This reflected TiDB Principle #2: Users are our first priority.
First, we tackled the incorrect execution plan. The direct way was to add index hints, which allowed users to select the optimal index. But that was just a makeshift solution, because sometimes users might not be able to use hints. The permanent solution was to switch TiDB from rule-based optimization to cost-based optimization. This could solve the problem once and for all, but it was surely difficult to achieve. We are still working on this solution.
Secondly, to address the uneven hotspot issue, we developed the hotspot scheduler. The hotspot scheduler counts and monitors the hotspots emerging in the system, quickly migrates the hotspots, and balances the pressure on each node.
Thirdly, we tackled the Raftstore’s single thread bottleneck. We spent over a year working on the single thread of Raftstore. We made the time-consuming computation in the Raftstore threads asynchronous and offloaded it to other threads. The optimization took so long because we valued stability the most. Even though Raft is simpler than Paxos, its implementation is still complicated. To support multi-threading in a sophisticated system and optimize the performance, we must be patient.
Lastly, the slow report generation problem. It was a hard nut to crack, and we are still cracking it even today. On one hand, we must greatly improve TiDB’s analytical ability. On the other hand, the system must be highly parallel and make full use of multiple cores. Simply by configuring parameters, TiDB can perform scans concurrently.
With all the above problems solved, we let out a sigh of relief. But that relief lasted less than a week. We were again overwhelmed by more user feedback. As our user base grew, users reported problems faster than we could handle them.
More voices coming
Because we stayed close to our users, we heard their voices early. Another batch of feedback came in:
- When users ran a complex query, the OLTP workloads had higher latency.
- Complex SQL statements occupied a large portion of resources.
- The reporting was not in real time.
- Users wanted the view and window functions.
- Better compatibility and more features: table partition and pessimistic concurrency control.
- Users wanted to quickly import hundreds of terabytes of data.
- Parallel garbage collection was no longer enough.
It would be impossible for PingCAP, a small team back then, to satisfy so many requirements. So we asked ourselves two questions:
- What did our users want in common?
- How could we solve the problem at its root?
Here came TiDB Principle #3: Solve the problem at its root. Among all the problems listed above, users really wanted three things: performance, isolation, and functionality. By virtue of TiDB’s architecture, we can achieve better performance and isolation at the same time. Then, based on that, we can add more functions.
We provided a Raft-based solution. The Raft consensus algorithm has a Learner role, which replicates logs from the Leader but doesn’t participate in Leader election. With this role, we could add a columnar replica in TiDB and meet multiple requirements at the same time:
- Complex queries were faster. The columnar storage engine is more suited to OLAP workloads.
- The Raft protocol ensures that data read from the Learner replica is strongly consistent. The Leader knows how much data is replicated to the Learner and when the Learner can respond to read requests.
- The log is replicated from the Leader to the Learner via streaming. The latency is low, so users can read the data in real time.
- OLAP requests access data from the Learner replica, and OLTP requests access data from the Leader and Follower replicas. The resources are isolated, and the two types of workloads rarely affect each other.
With just one well-designed stone, we killed more than two birds. This solution was later named TiFlash, a columnar store extension for TiDB. We also published a paper on VLDB, which explained in detail how we implemented the Raft-based HTAP database.
What’s next
By then we had successfully built a database that’s beyond our expectations. But that wasn’t enough. In the next post, I’ll show you two more principles of TiDB and explain how we came to shape TiDB the way it is today.
TiDB Dedicated
A fully-managed cloud DBaaS for predictable workloads
TiDB Serverless
A fully-managed cloud DBaaS for auto-scaling workloads