在 TiDB 源码阅读系列文章(七)基于规则的优化 一文中,我们介绍了几种 TiDB 中的逻辑优化规则,包括列剪裁,最大最小消除,投影消除,谓词下推和构建节点属性,本篇将继续介绍更多的优化规则:聚合消除、外连接消除和子查询优化。
聚合消除
聚合消除会检查 SQL 查询中 Group By 语句所使用的列是否具有唯一性属性,如果满足,则会将执行计划中相应的 LogicalAggregation 算子替换为 LogicalProjection 算子。这里的逻辑是当聚合函数按照具有唯一性属性的一列或多列分组时,下层算子输出的每一行都是一个单独的分组,这时就可以将聚合函数展开成具体的参数列或者包含参数列的普通函数表达式,具体的代码实现在 rule_aggregation_elimination.go 文件中。下面举一些具体的例子。
例一:
下面这个 Query 可以将聚合函数展开成列的查询:
select max(a) from t group by t.pk;被等价地改写成:
select a from t;例二:
下面这个 Query 可以将聚合函数展开为包含参数列的内置函数的查询:
select count(a) from t group by t.pk;被等价地改写成:
select if(isnull(a), 0, 1) from t;这里其实还可以做进一步的优化:如果列 a 具有 Not Null 的属性,那么可以将 if(isnull(a), 0, 1) 直接替换为常量 1。
另外提一点,对于大部分聚合函数,参数的类型和返回结果的类型一般是不同的,所以在展开聚合函数的时候一般会在参数列上构造 cast 函数做类型转换,展开后的表达式会保存在作为替换 LogicalAggregation 算子的 LogicalProjection 算子中。
这个优化过程中,有一点非常关键,就是如何知道 Group By 使用的列是否满足唯一性属性,尤其是当聚合算子的下层节点不是 DataSource 的时候?我们在 (七)基于规则的优化 一文中的“构建节点属性”章节提到过,执行计划中每个算子节点会维护这样一个信息:当前算子的输出会按照哪一列或者哪几列满足唯一性属性。因此,在聚合消除中,我们可以通过查看下层算子保存的这个信息,再结合 Group By 用到的列判断当前聚合算子是否可以被消除。
外连接消除
不同于 (七)基于规则的优化 一文中“谓词下推”章节提到的将外连接转换为内连接,这里外连接消除指的是将整个连接操作从查询中移除。
外连接消除需要满足一定条件:
- 条件 1 :
LogicalJoin的父亲算子只会用到LogicalJoin的 outer plan 所输出的列 - 条件 2 :
- 条件 2.1 :
LogicalJoin中的 join key 在 inner plan 的输出结果中满足唯一性属性 - 条件 2.2 :
LogicalJoin的父亲算子会对输入的记录去重
- 条件 2.1 :
条件 1 和条件 2 必须同时满足,但条件 2.1 和条件 2.2 只需满足一条即可。
满足条件 1 和 条件 2.1 的一个例子:
select t1.a from t1 left join t2 on t1.b = t2.pk;可以被改写成:
select t1.a from t1;满足条件 1 和条件 2.2 的一个例子:
select distinct(t1.a) from t1 left join t2 on t1.b = t2.b;可以被改写成:
select distinct(t1.a) from t1;具体的原理是,对于外连接,outer plan 的每一行记录肯定会在连接的结果集里出现一次或多次,当 outer plan 的行不能找到匹配时,或者只能找到一行匹配时,这行 outer plan 的记录在连接结果中只出现一次;当 outer plan 的行能找到多行匹配时,它会在连接结果中出现多次;那么如果 inner plan 在 join key 上满足唯一性属性,就不可能存在 outer plan 的行能够找到多行匹配,所以这时 outer plan 的每一行都会且仅会在连接结果中出现一次。同时,上层算子只需要 outer plan 的数据,那么外连接可以直接从查询中被去除掉。同理就可以很容易理解当上层算子只需要 outer plan 的去重后结果时,外连接也可以被消除。
这部分优化的具体代码实现在 rule_join_elimination.go 文件中。
子查询优化 / 去相关
子查询分为非相关子查询和相关子查询,例如:
-- 非相关子查询
select * from t1 where t1.a > (select t2.a from t2 limit 1);
-- 相关子查询
select * from t1 where t1.a > (select t2.a from t2 where t2.b > t1.b limit 1);对于非相关子查询, TiDB 会在 expressionRewriter 的逻辑中做两类操作:
-
子查询展开
即直接执行子查询获得结果,再利用这个结果改写原本包含子查询的表达式;比如上述的非相关子查询,如果其返回的结果为一行记录 “1” ,那么整个查询会被改写为:
select * from t1 where t1.a > 1;详细的代码逻辑可以参考 expression_rewriter.go 中的 handleScalarSubquery 和 handleExistSubquery 函数。
-
子查询转为 Join
对于包含 IN (subquery) 的查询,比如:
select * from t1 where t1.a in (select t2.a from t2);会被改写成:
select t1.* from t1 inner join (select distinct(t2.a) as a from t2) as sub on t1.a = sub.a;如果
t2.a满足唯一性属性,根据上面介绍的聚合消除规则,查询会被进一步改写成:select t1.* from t1 inner join t2 on t1.a = t2.a;这里选择将子查询转化为 inner join 的 inner plan 而不是执行子查询的原因是:以上述查询为例,子查询的结果集可能会很大,展开子查询需要一次性将
t2的全部数据从 TiKV 返回到 TiDB 中缓存,并作为t1扫描的过滤条件;如果将子查询转化为 inner join 的 inner plan ,我们可以更灵活地对t2选择访问方式,比如我们可以对 join 选择IndexLookUpJoin实现方式,那么对于拿到的每一条t1表数据,我们只需拿t1.a作为 range 对t2做一次索引扫描,如果t1表很小,相比于展开子查询返回t2全部数据,我们可能总共只需要从t2返回很少的几条数据。注意这个转换的结果不一定会比展开子查询更好,其具体情况会受
t1表和t2表数据的影响,如果在上述查询中,t1表很大而t2表很小,那么展开子查询再对t1选择索引扫描可能才是最好的方案,所以现在有参数控制这个转化是否打开,详细的代码可以参考 expression_rewriter.go 中的 handleInSubquery 函数。
对于相关子查询,TiDB 会在 expressionRewriter 中将整个包含相关子查询的表达式转化为 LogicalApply 算子。LogicalApply 算子是一类特殊的 LogicalJoin ,特殊之处体现在执行逻辑上:对于 outer plan 返回的每一行记录,取出相关列的具体值传递给子查询,再执行根据子查询生成的 inner plan ,即 LogicalApply 在执行时只能选择类似循环嵌套连接的方式,而普通的 LogicalJoin 则可以在物理优化阶段根据代价模型选择最合适的执行方式,包括 HashJoin,MergeJoin 和 IndexLookUpJoin,理论上后者生成的物理执行计划一定会比前者更优,所以在逻辑优化阶段我们会检查是否可以应用“去相关”这一优化规则,试图将 LogicalApply 转化为等价的 LogicalJoin 。其核心思想是将 LogicalApply 的 inner plan 中包含相关列的那些算子提升到 LogicalApply 之中或之上,在算子提升后如果 inner plan 中不再包含任何的相关列,即不再引用任何 outer plan 中的列,那么 LogicalApply 就会被转换为普通的 LogicalJoin ,这部分代码逻辑实现在 rule_decorrelate.go 文件中。
具体的算子提升方式分为以下几种情况:
-
inner plan 的根节点是
LogicalSelection则将其过滤条件添加到
LogicalApply的 join condition 中,然后将该LogicalSelection从 inner plan 中删除,再递归地对 inner plan 提升算子。以如下查询为例:
select * from t1 where t1.a in (select t2.a from t2 where t2.b = t1.b);其生成的最初执行计划片段会是:
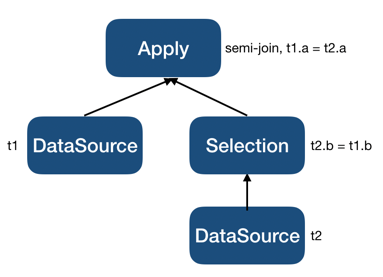
LogicalSelection提升后会变成如下片段: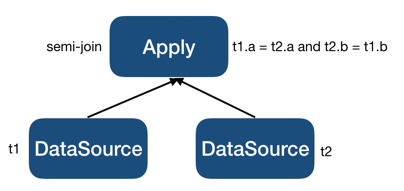
到此 inner plan 中不再包含相关列,于是
LogicalApply会被转换为如下 LogicalJoin :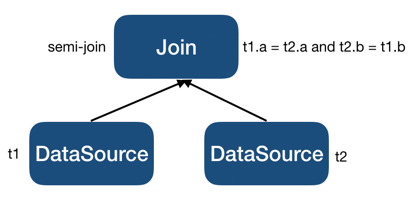
-
inner plan 的根节点是
LogicalMaxOneRow即要求子查询最多输出一行记录,比如这个例子:
select *, (select t2.a from t2 where t2.pk = t1.a) from t1;因为子查询出现在整个查询的投影项里,所以
expressionRewriter在处理子查询时会对其生成的执行计划在根节点上加一个LogicalMaxOneRow限制最多产生一行记录,如果在执行时发现下层输出多于一行记录,则会报错。在这个例子中,子查询的过滤条件是t2表的主键上的等值条件,所以子查询肯定最多只会输出一行记录,而这个信息在“构建节点属性”这一步时会被发掘出来并记录在算子节点的MaxOneRow属性中,所以这里的LogicalMaxOneRow节点实际上是冗余的,于是我们可以将其从 inner plan 中移除,然后再递归地对 inner plan 做算子提升。 -
inner plan 的根节点是
LogicalProjection则首先将这个投影算子从 inner plan 中移除,再根据
LogicalApply的连接类型判断是否需要在LogicalApply之上再加上一个LogicalProjection,具体来说是:对于非 semi-join 这一类的连接(包括 inner join 和 left join ),inner plan 的输出列会保留在LogicalApply的结果中,所以这个投影操作需要保留,反之则不需要。最后,再递归地对删除投影后的 inner plan 提升下层算子。 -
inner plan 的根节点是
LogicalAggregation
-
首先我们会检查这个聚合算子是否可以被提升到
LogicalApply之上再执行。以如下查询为例:select *, (select sum(t2.b) from t2 where t2.a = t1.pk) from t1;其最初生成的执行计划片段会是:
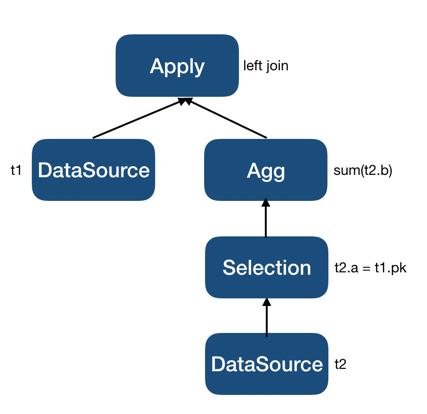
将聚合提升到
LogicalApply后的执行计划片段会是: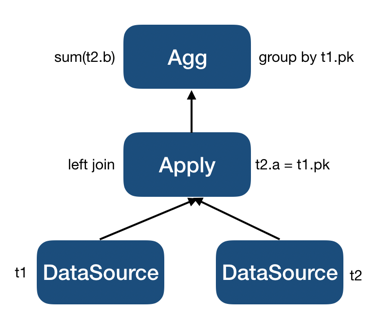
即先对
t1和t2做连接,再在连接结果上按照t1.pk分组后做聚合。这里有两个关键变化:第一是不管提升前LogicalApply的连接类型是 inner join 还是 left join ,提升后必须被改为 left join ;第二是提升后的聚合新增了Group By的列,即要按照 outer plan 传进 inner plan 中的相关列做分组。这两个变化背后的原因都会在后面进行阐述。因为提升后 inner plan 不再包含相关列,去相关后最终生成的执行计划片段会是: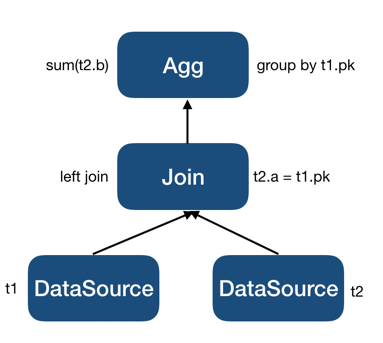
聚合提升有很多限定条件:
-
LogicalApply的连接类型必须是 inner join 或者 left join 。LogicalApply是根据相关子查询生成的,只可能有 3 类连接类型,除了 inner join 和 left join 外,第三类是 semi join (包括SemiJoin,LeftOuterSemiJoin,AntiSemiJoin,AntiLeftOuterSemiJoin),具体可以参考expression_rewriter.go中的代码,限于篇幅在这里就不对此做展开了。对于 semi join 类型的LogicalApply,因为 inner plan 的输出列不会出现在连接的结果中,所以很容易理解我们无法将聚合算子提升到LogicalApply之上。 -
LogicalApply本身不能包含 join condition 。以上面给出的查询为例,可以看到聚合提升后会将子查询中包含相关列的过滤条件 (t2.a = t1.pk) 添加到LogicalApply的 join condition 中,如果LogicalApply本身存在 join condition ,那么聚合提升后聚合算子的输入(连接算子的输出)就会和在子查询中时聚合算子的输入不同,导致聚合算子结果不正确。 -
子查询中用到的相关列在 outer plan 输出里具有唯一性属性。以上面查询为例,如果
t1.pk不满足唯一性,假设t1有两条记录满足t1.pk = 1,t2只有一条记录{ (t2.a: 1, t2.b: 2) },那么该查询会输出两行结果{ (sum(t2.b): 2), (sum(t2.b): 2) };但对于聚合提升后的执行计划,则会生成错误的一行结果{ (sum(t2.b): 4) }。当t1.pk满足唯一性后,每一行 outer plan 的记录都对应连接结果中的一个分组,所以其聚合结果会和在子查询中的聚合结果一致,这也解释了为什么聚合提升后需要按照t1.pk做分组。 -
聚合函数必须满足当输入为
null时输出结果也一定是null。这是为了在子查询中没有匹配的特殊情况下保证结果的正确性,以上面查询为例,当t2表没有任何记录满足t2.a = t1.pk时,子查询中不管是什么聚合函数都会返回null结果,为了保留这种特殊情况,在聚合提升的同时,LogicalApply的连接类型会被强制改为 left join(改之前可能是 inner join ),所以在这种没有匹配的情况下,LogicalApply输出结果中 inner plan 部分会是null,而这个null会作为新添加的聚合算子的输入,为了和提升前结果一致,其结果也必须是null。
-
-
对于根据上述条件判定不能提升的聚合算子,我们再检查这个聚合算子的子节点是否为
LogicalSelection,如果是,则将其从 inner plan 中移除并将过滤条件添加到LogicalApply的 join condition 中。这种情况下LogicalAggregation依然会被保留在 inner plan 中,但会将LogicalSelection过滤条件中涉及的 inner 表的列添加到聚合算子的Group By中。比如对于查询:select *, (select count(*) from t2 where t2.a = t1.a) from t1;其生成的最初的执行计划片段会是:
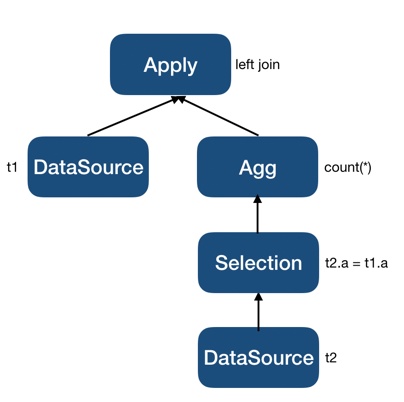
因为聚合函数是
count(*),不满足当输入为null时输出也为null的条件,所以它不能被提升到LogicalApply之上,但它可以被改写成: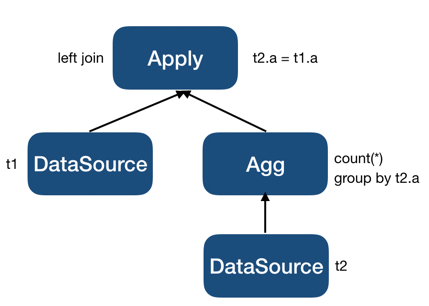
注意
LogicalAggregation的Group By新加了t2.a,这一步将原本的先做过滤再做聚合转换为了先按照t2.a分组做聚合,再将聚合结果与t1做连接。LogicalSelection提升后 inner plan 已经不再依赖 outer plan 的结果了,整个查询去相关后将会变为: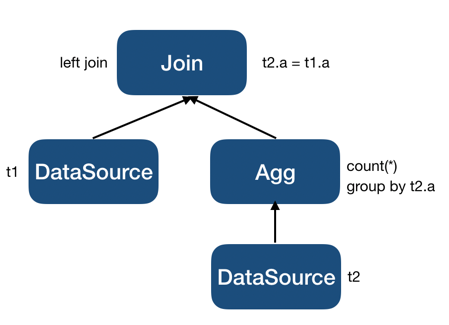
总结
这是基于规则优化的第二篇文章,后续我们还将介绍更多逻辑优化规则:聚合下推,TopN 下推和 Join Reorder 。
点击查看更多 TiDB 源码阅读系列文章
目录